The Challenge with Traditional Architectures
In the world of Java Enterprise development, many of us began our journey with the classic N-tier architecture and the CRUD (Create, Read, Update, Delete) model. We build a single, unified data model—often represented by JPA entities—and use it for everything. A User entity is used to register a new user, update their profile, delete their account, and display their details on a dashboard. While simple and effective for basic applications, this one-model-fits-all approach begins to crack under the pressure of complexity and scale.
As business logic grows, the model becomes a battleground of competing concerns. The write-side needs rich validation, business rules, and invariants, leading to a complex object graph. The read-side, however, needs fast, denormalized data tailored for specific UI screens, often requiring just a few fields from multiple related entities. Trying to serve both masters with a single model leads to performance bottlenecks, overly complex queries, and a codebase that’s difficult to maintain and reason about. This is where architectural Java Design Patterns come into play, offering a more sophisticated solution. The Command Query Responsibility Segregation (CQRS) pattern provides a powerful alternative for building robust, scalable, and maintainable Java Microservices and monolithic applications alike.
Section 1: Understanding the Core of CQRS
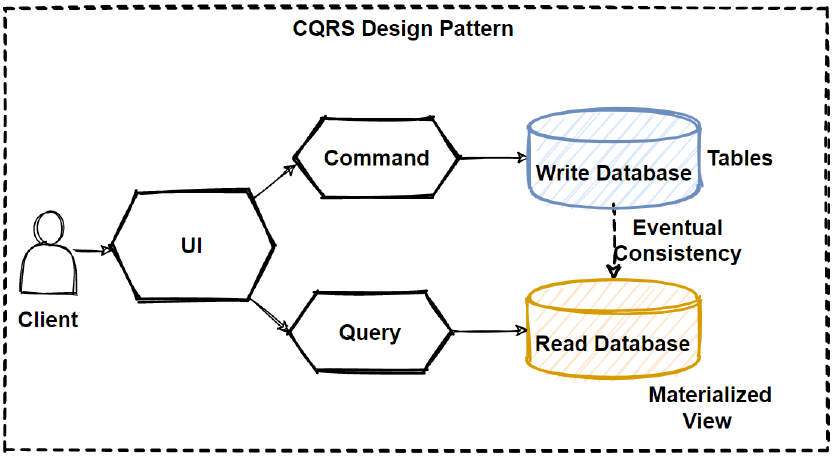
CQRS is an architectural pattern that separates the model for updating data from the model for reading data. The name itself is a mouthful, but the concept is beautifully simple: divide your application’s operations into two distinct categories: Commands and Queries.
What is CQRS?
At its heart, CQRS is based on the principle that you can use a different model to update information than the model you use to read it. This is a departure from the traditional approach where a single object-relational mapping (ORM) entity handles both reading and writing.
- Commands: These are operations that change the state of the system. They are task-based and imperative, like
CreateOrderCommandorUpdateCustomerAddressCommand. Commands should not return data; they typically return void or a simple acknowledgment of completion (e.g., the ID of the created entity). - Queries: These are operations that retrieve data and read the state of the system. They are side-effect-free, meaning they do not alter any state. Queries return Data Transfer Objects (DTOs) tailored specifically for the consumer (e.g., a UI component).
This separation allows you to optimize each side independently. The write model can be a fully normalized, behavior-rich domain model focused on enforcing business rules, while the read model can be a highly denormalized, flat structure optimized for fast queries.
Commands vs. Queries: A Practical Distinction
Let’s illustrate this with a simple e-commerce example. In Java 17 and later, records are an excellent choice for creating immutable DTOs for commands and queries.
A command to create a product is focused on intent and carries the necessary data to perform the action.
// Command: Represents an intent to change state
public record CreateProductCommand(
String name,
String description,
BigDecimal initialPrice,
int initialStock
) {
// Constructor with validation
public CreateProductCommand {
if (name == null || name.isBlank()) {
throw new IllegalArgumentException("Product name cannot be empty.");
}
if (initialPrice == null || initialPrice.compareTo(BigDecimal.ZERO) <= 0) {
throw new IllegalArgumentException("Initial price must be positive.");
}
}
}Conversely, a query might need to fetch a summarized view of a product for a list display. This model is shaped by the needs of the UI, not the rules of the domain.
// Query Read Model (DTO): A projection of data for a specific use case
public record ProductSummaryView(
UUID productId,
String productName,
BigDecimal currentPrice,
String status
) {}Notice the clear separation. The command is about “doing something,” while the query DTO is about “showing something.” There is no single Product class trying to do both.
Section 2: Implementing CQRS in a Spring Boot Application
Let’s bring theory into practice by building a simple CQRS-style service using Spring Boot, Spring Data JPA, and Hibernate. We’ll create separate paths for writing product data and reading it.
Structuring the Write Model (Commands)
The write side focuses on transactionality and consistency. We use a rich JPA entity that encapsulates business logic.
First, our JPA entity for the write model:
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
import java.math.BigDecimal;
import java.util.UUID;
@Entity
public class Product {
@Id
private UUID id;
private String name;
private String description;
private BigDecimal price;
private int stock;
// Protected constructor for JPA
protected Product() {}
// Factory method to create a product, enforcing invariants
public static Product create(String name, String description, BigDecimal price, int stock) {
// Business rule enforcement
if (stock < 0) throw new IllegalStateException("Stock cannot be negative.");
Product product = new Product();
product.id = UUID.randomUUID();
product.name = name;
product.description = description;
product.price = price;
product.stock = stock;
return product;
}
public void changePrice(BigDecimal newPrice) {
if (newPrice.compareTo(BigDecimal.ZERO) <= 0) {
throw new IllegalStateException("Price must be positive.");
}
this.price = newPrice;
}
// other business methods...
// getters...
}Next, a command handler service processes the CreateProductCommand. This service contains the business logic for the write operation.
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.UUID;
@Service
public class ProductCommandHandler {
private final ProductRepository productRepository;
public ProductCommandHandler(ProductRepository productRepository) {
this.productRepository = productRepository;
}
@Transactional
public UUID handle(CreateProductCommand command) {
Product product = Product.create(
command.name(),
command.description(),
command.initialPrice(),
command.initialStock()
);
productRepository.save(product);
return product.getId();
}
}Building the Read Model (Queries)
The read side is all about speed and efficiency. We can bypass the rich Product entity and query directly into our ProductSummaryView DTO. This can be done with JPA Projections or even native SQL for maximum performance.
Here’s a Spring Data JPA repository with a custom query for the read model:
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.stereotype.Repository;
import java.util.List;
import java.util.Optional;
import java.util.UUID;
@Repository
public interface ProductQueryRepository extends JpaRepository<Product, UUID> {
// This query bypasses the full entity and projects directly into our DTO.
// It's highly optimized for the read operation.
@Query("""
SELECT new com.example.myapp.ProductSummaryView(p.id, p.name, p.price, CASE WHEN p.stock > 0 THEN 'IN_STOCK' ELSE 'OUT_OF_STOCK' END)
FROM Product p
WHERE p.id = :productId
""")
Optional<ProductSummaryView> findProductSummaryById(UUID productId);
@Query("""
SELECT new com.example.myapp.ProductSummaryView(p.id, p.name, p.price, CASE WHEN p.stock > 0 THEN 'IN_STOCK' ELSE 'OUT_OF_STOCK' END)
FROM Product p
""")
List<ProductSummaryView> findAllProductSummaries();
}The API Layer: A CQRS-enabled REST Controller
The RestController clearly exposes the separate command and query endpoints, making the API’s intent explicit.
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import java.net.URI;
import java.util.List;
import java.util.UUID;
@RestController
@RequestMapping("/api/products")
public class ProductController {
private final ProductCommandHandler commandHandler;
private final ProductQueryRepository queryRepository;
public ProductController(ProductCommandHandler commandHandler, ProductQueryRepository queryRepository) {
this.commandHandler = commandHandler;
this.queryRepository = queryRepository;
}
// COMMAND endpoint
@PostMapping
public ResponseEntity<Void> createProduct(@RequestBody CreateProductCommand command) {
UUID productId = commandHandler.handle(command);
return ResponseEntity.created(URI.create("/api/products/" + productId)).build();
}
// QUERY endpoint
@GetMapping("/{id}")
public ResponseEntity<ProductSummaryView> getProductSummary(@PathVariable UUID id) {
return queryRepository.findProductSummaryById(id)
.map(ResponseEntity::ok)
.orElse(ResponseEntity.notFound().build());
}
// QUERY endpoint for a list
@GetMapping
public ResponseEntity<List<ProductSummaryView>> getAllProductSummaries() {
return ResponseEntity.ok(queryRepository.findAllProductSummaries());
}
}Section 3: Advanced CQRS – Asynchronicity and Event Sourcing
While the basic implementation of CQRS is powerful, its true potential is unlocked when combined with asynchronous processing and patterns like Event Sourcing. This is where Java Concurrency and messaging systems become essential for building highly scalable Java Cloud applications.
Decoupling with Asynchronous Operations
In a high-throughput system, you may not want the client to wait for a command to be fully processed. You can accept the command, validate it, and then process it asynchronously. This can be achieved using message brokers like RabbitMQ/Kafka or even Java Async tools like CompletableFuture.
A key benefit is that the write model can be updated independently of the read model. After a command successfully executes, it can publish an event (e.g., ProductCreatedEvent). Other parts of the system, specifically the ones responsible for the read model, can listen for these events and update their data stores accordingly. This leads to an “eventually consistent” state between the write and read models, which is a common and acceptable trade-off in distributed systems.
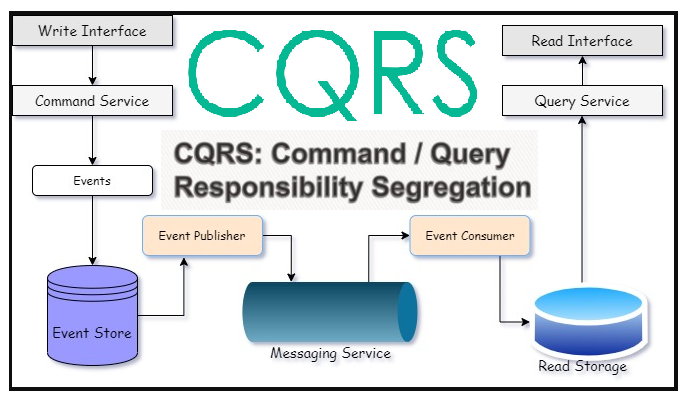
Updating the Read Model with Events
Event Sourcing is a pattern where we store the full history of changes (events) to an entity, rather than just its current state. The current state can be rebuilt at any time by replaying the events. In a CQRS context, these events are the perfect mechanism to update the read models (often called “projections”).
Here’s a conceptual example using Spring’s event mechanism. When our command handler saves a new product, it could also publish an event.
// A simple event DTO
public record ProductCreatedEvent(UUID productId, String name, BigDecimal price, int stock) {}
// Modified Command Handler
@Service
public class ProductCommandHandler {
private final ProductRepository productRepository;
private final ApplicationEventPublisher eventPublisher;
// ... constructor ...
@Transactional
public UUID handle(CreateProductCommand command) {
Product product = Product.create(/*...*/);
productRepository.save(product);
// Publish an event after the transaction commits
eventPublisher.publishEvent(new ProductCreatedEvent(
product.getId(), product.getName(), product.getPrice(), product.getStock()
));
return product.getId();
}
}
// A separate listener to update the read model
@Component
public class ReadModelProjectionUpdater {
private final ReadModelRepository readModelRepository; // A different repository, maybe even a different DB!
// ... constructor ...
@TransactionalEventListener
public void on(ProductCreatedEvent event) {
// Logic to update a denormalized read model in a separate table or database
// (e.g., Elasticsearch, MongoDB, or just another relational table)
System.out.println("Updating read model for new product: " + event.productId());
// readModelRepository.createOrUpdateProductView(...);
}
}This approach fully decouples the write and read sides. The read model can even live in a completely different database technology (e.g., Elasticsearch for fast text search) that is better suited for its query requirements.
Section 4: Best Practices, Pitfalls, and Optimization
CQRS is a powerful pattern, but it introduces complexity. It’s crucial to apply it judiciously and be aware of the trade-offs.
When to Use (and Not Use) CQRS
- Use CQRS for: Complex domains with significant business logic, applications requiring high performance and scalability on the read side, or collaborative domains where multiple actors operate on the same data.
– Avoid CQRS for: Simple CRUD-based applications. The added complexity of maintaining separate models, handling eventual consistency, and setting up the infrastructure is often not worth the benefit for simple use cases.
Ensuring Data Consistency
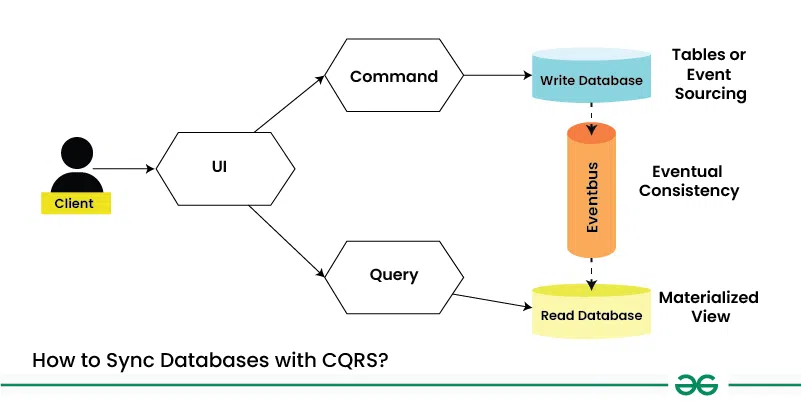
The biggest challenge in asynchronous CQRS is eventual consistency. The read model will lag slightly behind the write model. Your UI must be designed to handle this. For example, after a user submits a command, the UI can show a temporary “pending” state or use optimistic updates, rather than immediately expecting the updated data to be available for querying.
Testing CQRS Components
The separation of concerns in CQRS makes testing more focused. Using tools like JUnit and Mockito, you can:
- Test Command Handlers: Verify that the correct methods on the repository are called and that the handler throws exceptions for invalid commands. You are testing behavior and state changes.
- Test Query Handlers: Verify that given a certain state in the database, the handler returns the correctly shaped DTO. You are testing data retrieval and mapping.
- Test Projections: Verify that when a specific event is consumed, the read model is updated correctly.
Performance and Optimization
For Java Performance, CQRS offers many levers. The read side can be heavily optimized with caching (e.g., Redis or Caffeine), materialized views, or specialized read databases like Elasticsearch. Since read queries are side-effect-free, they are perfect candidates for aggressive caching strategies. JVM Tuning and garbage collection optimization become important for the command-processing side if it handles a high volume of state changes.
Conclusion: Embracing Architectural Flexibility
The CQRS design pattern is more than just a technical implementation; it’s a shift in mindset away from the one-size-fits-all model of traditional architectures. By separating commands from queries, you grant your Java Backend system the flexibility to evolve, scale, and perform under pressure. The write side can focus on upholding business integrity with a rich domain model, while the read side can be tailored for blazing-fast data retrieval, creating a better user experience.
While it introduces concepts like eventual consistency and requires a more thoughtful approach to system design, the benefits in complex domains are undeniable. For developers working with Java Spring Boot on modern, scalable applications, understanding and knowing when to apply CQRS is a critical skill. Start small, identify a bounded context in your application that would benefit from this separation, and explore how this powerful pattern can help you write more robust, maintainable, and performant code.