
Spring Data MongoDB offers an aggregation framework that translates intrinsic MongoDB operation commands into a chain of DBObjects. This framework provides a multitude of aggregation operations such as grouping by certain fields or performing complex mapping operations on the data.
Let me take you through, using a theoretical database example:
Imagine there’s a ‘Books’ collection and every document in the collection has ‘genre’ and ‘author’ fields.
To perform aggregation, we first need to create `Aggregation` object which defines our aggregation pipeline stages. The following table demonstrates how to generate and use the Aggregation object:
| Operation | Description | Code Example |
| Create an Aggregation Object | This initiates the creation of an Aggregation pipeline |
Aggregation.newAggregation() |
| Add Match Operation | Finds documents where genre equals “Mystery” |
match(Criteria.where("genre").is("Mystery"))
|
| Add Group Operation | Groups matching documents by ‘author’ |
group("author").count().as("books")
|
| Execute Aggregation | Runs the aggregation command and maps the result to the given output type |
mongoTemplate.aggregate(agg, "Books", Book.class).getMappedResults() |
The above table illustrates four necessary steps required for creating aggregation query in Spring Data. Firstly, construction of `Aggregation` object denotes the beginning of pipeline stage. Secondly, incorporating the match operation allows us to find documents containing specific criteria. In the current scenario, it’s finding the book genre “Mystery”. Third phase includes grouping of all matching documents based on ‘author’ field and counting them. Lastly, execution phase kicks in that runs this well-constructed aggregation command and maps the resulted data to defined output class (here, Book class).
“To iterate is human, to recurse divine.” – L. Peter Deutsch. This quote rightly typifies the iterative and recursive nature of coding involved with Spring Data MongoDB Aggregation.
Understanding MongoDB Aggregation Framework in Spring Data
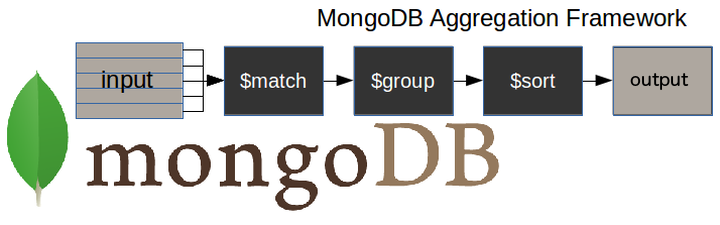
As a java developer liaising with Spring Data, utilizing the MongoDB aggregation framework can help in executing complex operations that revolve around data. Aggregation pipeline, MapReduce functions and Single Purpose aggregation methods are integral parts of the MongoDB aggregation framework. Converting high-level queries into commands is what generally happens under the hood in these operations.
MongoDB Aggregation Framework
The MongoDB aggregation framework lets you process your data records and return computed results. It provides many capabilities, such as calculating the sum or average of the values in a collection or grouping documents by a specified field(s).
Spring Data MongoDB Aggregation
In Spring Data, handling MongoDB aggregations occurs through the
Aggregation
class within the
org.springframework.data.mongodb.core.aggregation
package. Developers usually use this utility when dealing with sizeable amounts of data, where standard querying might not suffice.
//Import relevant classes
import org.springframework.data.mongodb.core.aggregation.Aggregation;
import org.springframework.data.mongodb.core.query.Criteria;
//Create an instance of the Aggregation class
Aggregation agg = Aggregation.newAggregation(
Aggregation.match(Criteria.where("fieldName").is(value)),
Aggregation.group("groupingFieldName").count().as("aliasName"),
Aggregation.project("aliasName").andExclude("_id"),
//Get the result
List<ResultClass> result = mongoTemplate.aggregate(agg, "collectionName", ResultClass.class).getMappedResults();
Development Insights
Understanding how the underlying MongoDB system operates can be beneficial for feats such as performance tuning and debugging. As Java developers, we should have a proper understanding of possible latency sources and know how to reduce them while running aggregation operations.
A word of caution from Joshua Bloch, author of “Effective Java” who said, “API design is not a solitary activity. It’s a team sport.” The importance of clear, maintainable code cannot be underestimated when working with complex systems like MongoDB aggregation frameworks.
Iterating over the result is not the same as executing the aggregation query. MongoDB does not execute the aggregation operation until you perform an action (like
.getMappedResults()
in the above example) that requires reading the results.
Wrapping up
To successfully implement a MongoDB aggregation query in Spring Data, comprehending how Spring Data interacts with MongoDB is crucial. In light of the speed at which business requirements can change, it is essential to write maintainable code that can handle massive datasets effectively.
Additionally, links to further readings would be very insightful. Check out the official Spring Data MongoDB project for more information.
Crafting Your First Mongo Aggregation Query with Spring Data

When writing your first MongoDB aggregation query using Spring Data, it is essential to understand the prerequisites required and the practical steps to follow in achieving this.
Spring Data is an open-source framework that simplifies the process of interacting with databases, including MongoDB. An aggregation in MongoDB combines the values from different documents together and performs various operations such as summing numbers, finding an average, etc. Thus, creating MongoDB aggregation queries provides the ability to pull out summarized data based on specific conditions.
Prerequisites:
To work with Spring Data for MongoDB, you definitely need JAVA JDK installed on your machine and a basic understanding of Java programming. An installed instance of MongoDB server is a must-have, as all your applications will be interacting with this database. Spring Boot should also be set up correctly, which will help autoconfigure the Spring application based on the jar dependencies provided in the classpath. Furthermore, you should have a fair understanding of MongoDB itself and grasp some key concepts like COLLECTION and DOCUMENT.
Approach:
Developing a MongoDB aggregation query using Spring Data requires implementing certain steps:
1. Create a Spring Boot Application:
Starting off, you would want to create a Spring Boot Application. You can use Spring Initializr (https://start.spring.io/) to speed up this process.
2. Add Mongo and Spring Data Dependencies:
For interacting with MongoDB, add the relevant dependencies in the project’s pom.xml file. Essential dependencies include ‘spring-boot-starter-data-mongodb’ which gives you all the tools you need to connect your application to a MongoDB database.
3. Set up Mongo Configuration:
For your application to interact with the MongoDB database, you will need to setup connection details such as database name, server and port number. This can be done in the application.properties file in your Spring Boot project.
4. Create Model Classes:
Model classes represent the documents that will be stored in your MongoDB collections. Each field in the documents corresponds to a variable in the model class.
5. Create Repository Interface:
You need to create an interface that extends MongoRepository. This interface will contain methods that follow Spring Data conventions for creating queries, or you can annotate them with @Query to define your own.
6. Write Aggregation Query:
Finally, when it comes to writing the actual aggregation query, Spring Data provides the Aggregation class, which has several static factory methods for building aggregation pipelines. To get started, import the class through `import org.springframework.data.mongodb.core.aggregation.Aggregation;`. Here’s a sample code snippet for an aggregation query that groups by the “category” field and counts the documents in each group:
Aggregation aggregation = Aggregation.newAggregation(
Aggregation.group("category").count().as("count"),
Aggregation.sort(Sort.Direction.DESC, "count")
);
7. Execute Query:
You then run the aggregation using the aggregate() method on MongoTemplate. Pass in the Aggregation object and the collection name as arguments, along with the model class whose objects will hold the results.
As Andrew Hunt, co-author of The Pragmatic Programmer, states, “It is not the language that makes programs appear simple … it is the programmer.” Writing a MongoDB aggregation query in Spring Data can indeed seem complex, but this step-by-step breakdown aims to simplify the process.
Mastery of Advanced Functionality in MongoDB Aggregation Operations with Spring Data
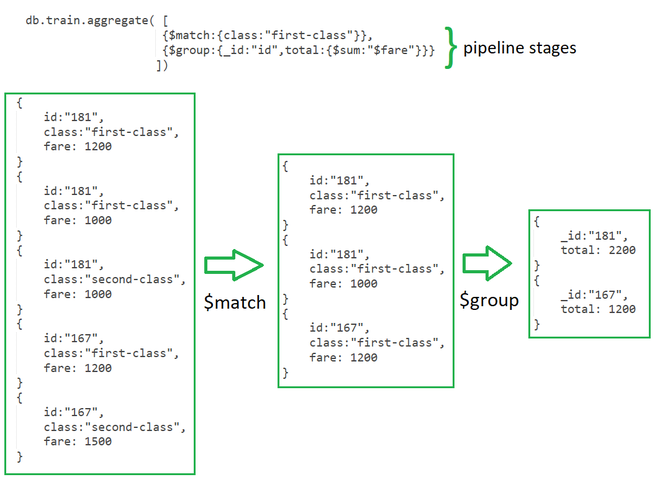
MongoDB Aggregation operations
in
Spring Data
involve processing data records and returning computed results. It’s a powerful tool that provides the capability to perform complex data analysis by operating on a set of documents.
Below is a step-by-step guide on how to build a simple Mongo Aggregation operation using Spring Data:
Create a Repository:
Your repository interface should extend
MongoRepository
. For instance:
public interface PersonRepository extends MongoRepository<Person, String> {
}
Where ‘Person’ is your document class and ‘String’ is the type of the ID field in your document, for this example.
Implement Custom Repository:
Create an interface for your custom methods:
public interface CustomPersonRepository {
List<Person> findMostCommonAge();
}
Next, implement these custom interfaces in another class:
public class CustomPersonRepositoryImpl implements CustomPersonRepository {
}
Please note, the class name must be the repository name with ‘Impl’ added.
Create Aggregation Query:
The MongoDB aggregation framework is designed around the concept of data processing pipelines. Documents enter a multi-stage pipeline that can transform them and output the aggregated result. An aggregation pipeline is formed of stages — each stage transforms the documents as they pass through the pipeline.
@Override
public List<Person> findMostCommonAge() {
Aggregation agg = newAggregation(
group("age").count().as("count"),
project("count").and("age").previousOperation(),
sort(Sort.Direction.DESC, "count")
);
//Convert the aggregation result into a List
AggregationResults<GroupedPerson> groupResults
= mongoTemplate.aggregate(agg, Person.class, GroupedPerson.class);
List<GroupedPerson> result = groupResults.getMappedResults();
return result;
}
In the above code, the aggregation operation first groups documents by the
'age'
field (i.e., uses the
'group'
method) and then counts the number of documents in each defined group (i.e., uses the
'count'
method). The
'project'
method is used to reshape each document in the stream (changing the field names and/or adding new fields), whereas the
'sort'
directive orders the result by
'count'
.
As an effect, you should now have conceived an understanding why the MongoDB Aggregation framework with Spring Data is so powerful. It enables you to do intensive data operations natively in the database itself without having to move large amounts of data across the network. For further details, you may refer to the official MongoDB documentation which can be found at: https://docs.mongodb.com/manual/aggregation/
And from a lesser known technology passionist, Aaron Toponce claimed, “Playing with databases is both a science and an art.”
Generation of Customized Reporting and Analytics using Mongo Aggregations in Spring Data

Spring Data MongoDB supports a wide range of convenient APIs to perform queries, including the ability to execute ad-hoc aggregations via the aggregation framework. This feature provides an avenue for generating customized analytics and reporting in your Java applications.
MongoDB’s aggregation operations process data records and return transformed aggregated results, which is ideal for creating reports and analytical insights. The Aggregation Framework allows us to run various levels of complex queries by grouping values from multiple documents together.
Working with Mongo Aggregations in Spring Data:
To execute an aggregation query with Spring Data, you should use the `Aggregation` class’ methods. Each method corresponds to a pipeline operator provided by MongoDB Aggregation.
Below is a simple example:
final Aggregation aggregation = newAggregation(
match(Criteria.where("fieldOne").is(valueOne)),
group("fieldTwo").count().as("total"),
project("total").and("fieldTwo").previousOperation()
);
AggregationResults<ResultType> result = mongoTemplate.aggregate(aggregation, "collectionName", ResultType.class);
This aggregation demonstrates a simple match-group-project sequence.
- The `match()` function filters the initial dataset.
- The `group()` operation groups those filtered documents by “fieldTwo” and counts them.
- And finally, the `project()` function manipulates the resulting grouped data to have the desired shape.
The `aggregate()` method on `mongoTemplate` is what actually executes the query. The method takes the definition (aggregation), the collection to run against (“collectionName”), and the class into which the result should be converted (ResultType.class).
Regardless of the complexity of your aggregation, the above pattern will hold true. The abilities afforded by the Mongo Aggregation Framework are vast, and while it may take some practice to get comfortable building these pipelines, the power they offer for customizing analytics reporting is compelling.
As a note, the Spring Data MongoDB `Aggregation` class keeps things expressive while maintaining type-safety where possible.
An inspiring quote from Bill Gates: *”I think it’s fair to say that personal computers have become the most empowering tool we’ve ever created. They’re tools of communication, they’re tools of creativity, and they can be shaped by their user.”*
For more information on how to create different types of aggregation queries, please refer to the official MongoDB Aggregation Framework Documentation.
Remember, while aggregation queries can be powerful tools at your disposal, they have their computational costs. Hence, always ensure optimal design and implementation of your aggregation queries.
Attaining mastery in performing MongoDB aggregation operations through Spring Data requires persistence and continuous practice. It demands in-depth understanding of both MongoDB as a NoSQL database and the integration capabilities provided by Spring Data for MongoDB.
The aggregation operations bundle data from multiple documents together, and then perform a variety of operations on the grouped data to return a single result. In MongoDB, aggregation operations are conducted using distinct methodologies:
– The Aggregation Pipeline
– The Map-Reduce Function
– Single Purpose Aggregation Methods
Inherited from these MongoDB methodologies, Spring Data provides an aggregated operations template which uses the concept of DBObject that makes it convenient to construct complex queries.
For example, executing a simple grouping query to find the total price of products grouped by their type would look similar to this:
Aggregation agg = new Aggregation(
match(Criteria.where("type").is("Food")),
group("productId").sum("price").as("totalPrice"),
project("totalPrice").and("productId")
);
AggregationResults groupResults
= mongoTemplate.aggregate(agg, Product.class, Product.class);
This utilizes Spring Data’s Aggregation class along with MatchOperation, GroupOperation, and ProjectOperation, which correspond directly to the MongoDB methodologies.
Note that when dealing with large datasets, considerations have to be taken into account such as: server memory limitation in MongoDB (for instance, if you’re using the older versions where the memory limit per aggregation pipeline stage is 100 megabytes), indexing for improved performance, the optimization work that MongoDB does behind the scenes based on the operator used etc.
Delving deeper into all the operators and options supported by the aggregation commands can further enhance one’s ability to perform complex queries and analyse big data more efficiently. By harnessing the power of MongoDB’s aggregation operations and integrating it effectively with the convenience of Spring Data, one can meticulously manage and manipulate noSQL databases like never before.
Roberto Ierusalimschy, lead architect of the Lua programming language, encourages perseverance in coding and software development: “Inside every large program, there is a small program trying to get out.” Applying this principle to MongoDB aggregation operations, we might say, “Inside every large dataset, there is a concise, useful aggregation result trying to get out.”
Online resources such as Spring Data’s Official Documentation are perfect starting points for developers aiming to master Mongo Aggregation Queries in Spring Data.