Introduction to Modern Java Persistence
In the vast ecosystem of Java Development, managing data persistence has always been a critical challenge. For decades, developers wrestled with verbose SQL queries and complex JDBC boilerplate code to bridge the gap between object-oriented Java Programming and relational databases. This impedance mismatch often led to fragile architectures and maintenance nightmares. Enter the Java Persistence API (JPA), now known as Jakarta Persistence, a specification that revolutionized how Java Backend applications interact with data.
JPA provides a standard for object-relational mapping (ORM) in the Java Enterprise (Jakarta EE) platform. While JPA itself is merely a specification—a set of interfaces and rules—it relies on implementations like Hibernate, EclipseLink, or OpenJPA to do the heavy lifting. Today, when combined with Spring Boot and Spring Data, JPA offers a streamlined, powerful approach to database management that is essential for building scalable Java Microservices and robust Java REST APIs.
This article provides a deep dive into JPA, moving from core concepts to advanced implementation details. We will explore how to leverage Java Best Practices to optimize performance, handle complex relationships, and ensure your Java Architecture remains clean and maintainable. Whether you are transitioning from Java Basics to Java Advanced topics or looking to refine your existing skills, understanding JPA is non-negotiable for modern development.
Section 1: Core Concepts and Entity Mapping
At the heart of JPA lies the concept of the “Entity.” An entity is a lightweight, persistent domain object. From a Java Basics perspective, an entity is simply a POJO (Plain Old Java Object) annotated with specific metadata that tells the JPA provider how to map the class to a database table. Understanding the lifecycle of these entities is crucial for effective Java Web Development.
The Entity Lifecycle
JPA defines four distinct states for an entity:
- New (Transient): The object is created but not yet associated with an
EntityManageror a database record. - Managed (Persistent): The object is associated with an
EntityManagercontext. Any changes to the object will be automatically synchronized with the database upon transaction commit. - Detached: The object was previously managed but the context has closed. Changes are not tracked.
- Removed: The object is scheduled for deletion from the database.
Defining a Robust Entity
To define an entity, we use annotations from the javax.persistence (or jakarta.persistence in newer Java 17/Java 21 environments) package. A proper entity design is the foundation of Clean Code Java.
Below is an example of a properly mapped User entity. Note the use of Lombok (optional but common) to reduce boilerplate, and the careful definition of column constraints.
package com.example.demo.model;
import jakarta.persistence.*;
import java.time.LocalDateTime;
import java.util.Objects;
@Entity
@Table(name = "users", indexes = {
@Index(name = "idx_user_email", columnList = "email")
})
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, unique = true, length = 100)
private String email;
@Column(nullable = false)
private String passwordHash;
@Column(name = "created_at", nullable = false, updatable = false)
private LocalDateTime createdAt;
@Column(name = "is_active")
private boolean isActive = true;
// Lifecycle hooks for automatic timestamping
@PrePersist
protected void onCreate() {
this.createdAt = LocalDateTime.now();
}
// Standard Getters and Setters
public Long getId() { return id; }
public void setId(Long id) { this.id = id; }
public String getEmail() { return email; }
public void setEmail(String email) { this.email = email; }
// Ideally, use a library like BCrypt for Java Security
public void setPasswordHash(String passwordHash) { this.passwordHash = passwordHash; }
// hashCode and equals based on business key (email) or ID
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof User)) return false;
User user = (User) o;
return Objects.equals(email, user.email);
}
@Override
public int hashCode() {
return Objects.hash(email);
}
}In this example, we utilize @PrePersist to handle audit fields automatically. This is a common pattern in Java Database design to ensure data integrity without cluttering the service layer.
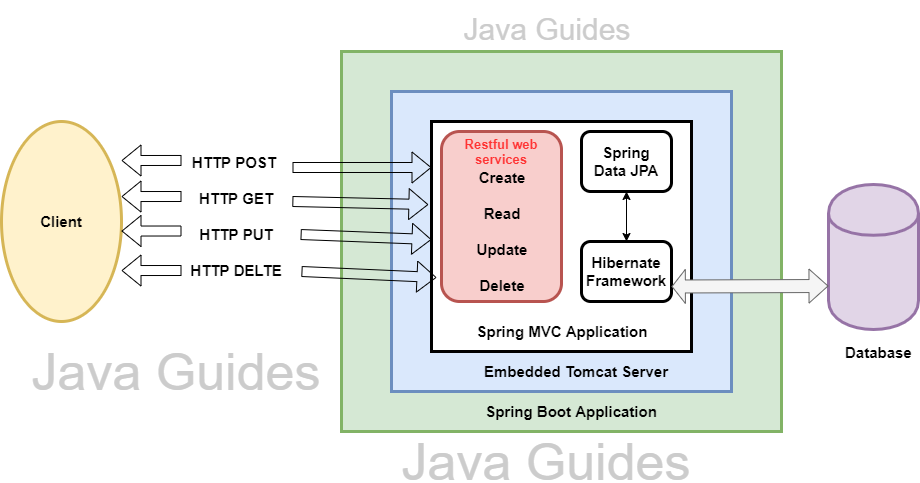
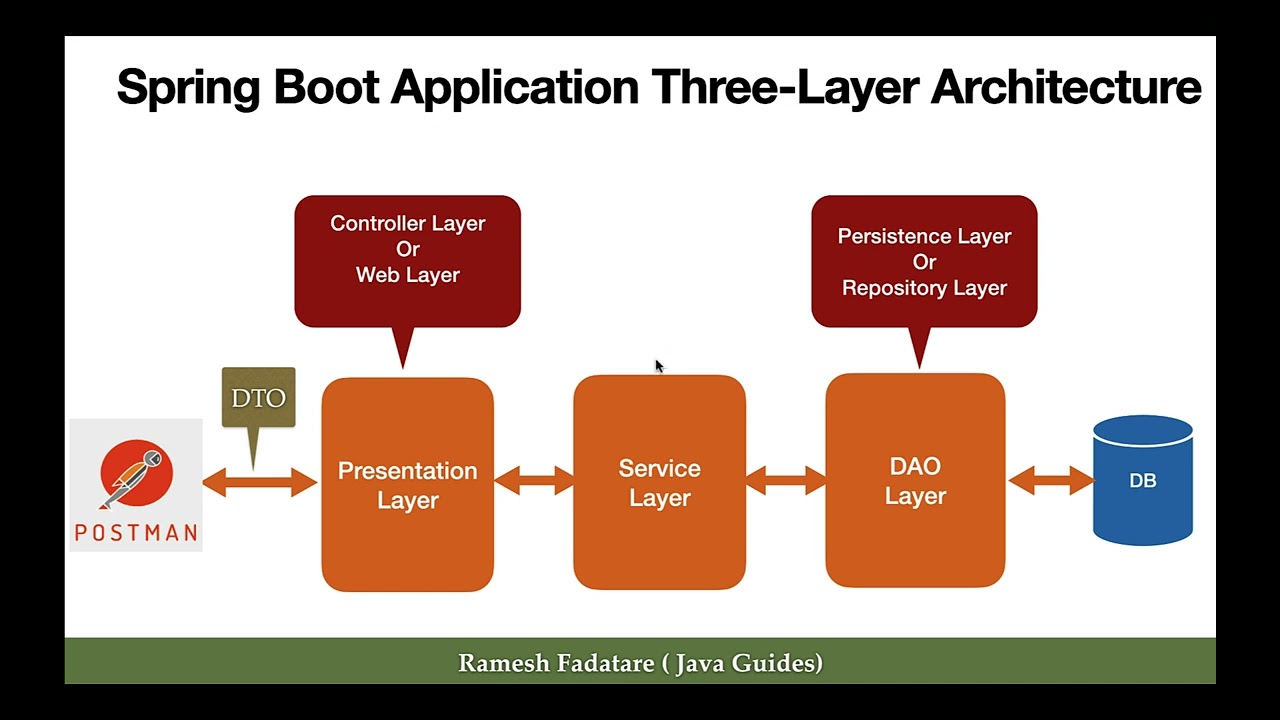
Section 2: Implementation with Spring Boot and Spring Data
While raw JPA requires manually managing the EntityManager and handling transactions, Spring Boot abstracts this complexity through Spring Data JPA. This framework significantly reduces the amount of code required to implement data access layers, allowing developers to focus on business logic rather than SQL mechanics.
Apple TV 4K with remote – New Design Amlogic S905Y4 XS97 ULTRA STICK Remote Control Upgrade …
The Repository Pattern
Spring Data JPA introduces the concept of the Repository interface. By simply extending JpaRepository, you gain access to standard CRUD operations (Create, Read, Update, Delete) without writing a single line of implementation code. This leverages Java Generics to provide type-safe database access.
Configuration and Dependency Management
To get started, you typically use Java Build Tools like Java Maven or Java Gradle. You would include the spring-boot-starter-data-jpa dependency and a database driver (e.g., PostgreSQL, MySQL, or H2). Spring Boot’s auto-configuration detects these libraries and configures the DataSource and EntityManagerFactory automatically.
Here is how a service layer interacts with the repository in a typical Java Microservices architecture:
package com.example.demo.service;
import com.example.demo.model.User;
import com.example.demo.repository.UserRepository;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
import java.util.Optional;
// The Repository Interface
// No implementation needed! Spring generates the proxy at runtime.
interface UserRepository extends org.springframework.data.jpa.repository.JpaRepository {
// Derived query method
Optional findByEmail(String email);
// Custom JPQL query
@org.springframework.data.jpa.repository.Query("SELECT u FROM User u WHERE u.isActive = true")
List findAllActiveUsers();
}
@Service
public class UserService {
private final UserRepository userRepository;
// Constructor injection - a Java Best Practice
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
@Transactional
public User registerUser(String email, String rawPassword) {
if (userRepository.findByEmail(email).isPresent()) {
throw new RuntimeException("User already exists");
}
User newUser = new User();
newUser.setEmail(email);
// Simulate password hashing for Java Security
newUser.setPasswordHash("hashed_" + rawPassword);
return userRepository.save(newUser);
}
@Transactional(readOnly = true)
public List getActiveDirectory() {
return userRepository.findAllActiveUsers();
}
} The @Transactional annotation is vital here. It defines the scope of a database transaction. If an exception (specifically a RuntimeException) occurs within the method, the transaction rolls back, ensuring atomicity. This declarative transaction management is a hallmark of Java Spring development.
Section 3: Advanced Techniques and Relationships
Real-world applications rarely consist of single, isolated tables. Mastering JPA requires a deep understanding of entity relationships and how to map them efficiently. Mismanaging relationships is the primary cause of Java Performance issues in database-driven applications.
Mapping Relationships
JPA supports several relationship types: @OneToOne, @OneToMany, @ManyToOne, and @ManyToMany. The most common pattern is a bidirectional One-to-Many relationship, such as an Author having many Books.
When mapping these, developers must decide between Lazy and Eager loading.
- Eager Loading: Fetches related data immediately with the parent. Convenient but can lead to loading too much data.
- Lazy Loading: Fetches related data only when accessed. This is the default for
@OneToManyand is generally preferred for performance, though it requires an active transaction session.
Advanced Querying with Specifications
For dynamic filtering—common in Java REST API search endpoints—hardcoded methods become unmanageable. Spring Data JPA Specifications (based on the JPA Criteria API) allow you to build queries programmatically. This is similar to building predicates in Java Streams.
Here is an example of a complex relationship mapping and a dynamic query approach:

Apple TV 4K with remote – Apple TV 4K 1st Gen 32GB (A1842) + Siri Remote – Gadget Geek
package com.example.demo.model;
import jakarta.persistence.*;
import java.util.ArrayList;
import java.util.List;
@Entity
public class Author {
@Id @GeneratedValue
private Long id;
private String name;
// Best Practice: Always cascade operations carefully
// orphanRemoval=true ensures child is deleted if removed from list
@OneToMany(mappedBy = "author", cascade = CascadeType.ALL, orphanRemoval = true, fetch = FetchType.LAZY)
private List books = new ArrayList<>();
// Helper methods to maintain bidirectional consistency
public void addBook(Book book) {
books.add(book);
book.setAuthor(this);
}
public void removeBook(Book book) {
books.remove(book);
book.setAuthor(null);
}
// Getters and setters...
}
@Entity
public class Book {
@Id @GeneratedValue
private Long id;
private String title;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "author_id")
private Author author;
public void setAuthor(Author author) { this.author = author; }
// Getters...
}
// Usage in a Service using Criteria Builder logic (simplified)
/*
Specification spec = (root, query, cb) -> {
return cb.like(root.get("title"), "%Java%");
};
List javaBooks = bookRepository.findAll(spec);
*/ Using helper methods like addBook ensures that the object graph remains consistent in memory before it is flushed to the database, preventing subtle bugs in your Java Logic.
Section 4: Best Practices and Optimization
Even with powerful frameworks, poor implementation can lead to sluggish applications. Optimizing JPA is a critical skill for Java Scalability and JVM Tuning.
The N+1 Select Problem
The most notorious issue in ORM frameworks is the N+1 select problem. This occurs when you fetch a list of N entities (1 query), and then iterate over them to access a lazily loaded relationship, triggering N additional queries. For a list of 1000 users, fetching their addresses could result in 1001 database calls.
Solution: Use JOIN FETCH in JPQL or Entity Graphs to load related data in a single query.
DTO Projections
Do not always return full Entities to the presentation layer or API consumers. Entities often contain more data than needed (like password hashes) or trigger lazy loading exceptions if accessed outside a transaction. Instead, use DTOs (Data Transfer Objects) or Records (introduced in recent Java versions).
Apple TV 4K with remote – Apple TV 4K iPhone X Television, Apple TV transparent background …
package com.example.demo.repository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.Repository;
import java.util.List;
// Java 17+ Record for immutable data carrier
public record AuthorSummary(String name, Long bookCount) {}
public interface AuthorRepository extends Repository {
// OPTIMIZATION 1: Solving N+1 Problem
// Fetches Author and Books in one SQL query
@Query("SELECT a FROM Author a LEFT JOIN FETCH a.books")
List findAllWithBooks();
// OPTIMIZATION 2: DTO Projection
// Fetches only specific fields, bypassing the overhead of managing Entity state
@Query("SELECT new com.example.demo.repository.AuthorSummary(a.name, COUNT(b)) " +
"FROM Author a LEFT JOIN a.books b GROUP BY a.name")
List getAuthorSummaries();
} Concurrency and Locking
In high-concurrency environments, such as Java Cloud deployments on AWS or Azure, data consistency is paramount. JPA supports Optimistic Locking using the @Version annotation. This adds a version column to the table. If two threads try to update the same row, the second one will fail with an OptimisticLockException, preventing lost updates.
Connection Pooling
While JPA handles the mapping, the underlying JDBC connection is managed by a pool. In Spring Boot, HikariCP is the default. Tuning HikariCP settings (max pool size, timeouts) is essential for Java DevOps and production stability. Ensure your pool size is calculated based on your database’s core count and I/O capabilities.
Conclusion
JPA, specifically when implemented via Hibernate and Spring Data, remains the cornerstone of Java Backend development. It abstracts the complexities of SQL, boosts developer productivity, and integrates seamlessly with the modern Java Spring ecosystem. However, it is not a “magic bullet.” To build high-performance applications, developers must look under the hood to understand entity lifecycles, fetch strategies, and transaction boundaries.
As the Java ecosystem evolves with Java 21 and beyond, introducing features like virtual threads (Project Loom), the blocking nature of JDBC and JPA is being challenged by reactive paradigms (R2DBC). However, for the vast majority of enterprise applications, the maturity, stability, and rich feature set of JPA make it the superior choice.
To master this technology, continue experimenting with advanced mappings, monitor your generated SQL using tools like P6Spy, and always validate your persistence layer with robust Java Testing using JUnit and Testcontainers. By adhering to these principles and Java Design Patterns, you will ensure your applications are not only functional but also scalable and maintainable for years to come.