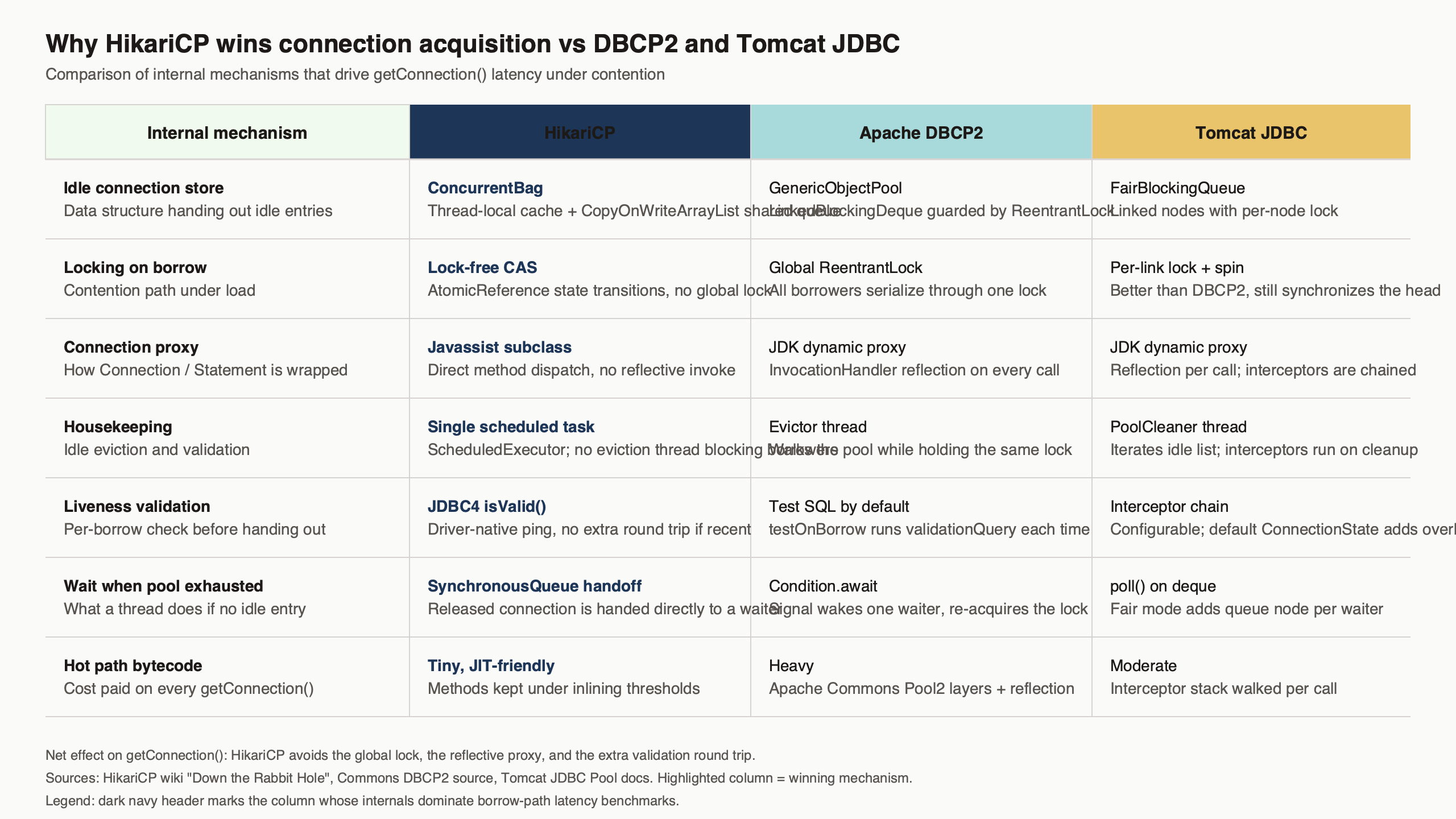
At first glance HikariCP looks faster because its pool is leaner, but the hidden mechanism is a borrow-time lock DBCP2 and Tomcat JDBC still take on every acquisition that HikariCP sidesteps entirely. The internal mechanics of HikariCP’s connection pool rely on ConcurrentBag, FastList, and Javassist-generated JDBC proxies — ThreadLocal reuse, CAS state changes, and direct dispatch instead of reflective invocation. The caveat: this gap shows up in borrow-heavy contended services with tight p99 budgets, not long-query workloads where the pool sits idle, so reach for HikariCP when contention is the bottleneck.
More on Hikaricp Internals Connection Pool.
Jump to
- The three structures that explain HikariCP’s acquisition win
- ConcurrentBag, layer by layer: how a borrow stays lock-free
- What DBCP2 and Tomcat JDBC do on the same path
- FastList and the Javassist proxy: why per-statement overhead matters
- Benchmarks that aren’t from 2017: methodology and what to measure
- Virtual threads and the ThreadLocal cache: is HikariCP still the right pick on Loom?
- When DBCP2 or Tomcat JDBC is actually the right call
- Configuring HikariCP so the bag stays hot
- Further reading
- ConcurrentBag hot path:
ConcurrentBaggoes ThreadLocal cache → shared list CAS scan → SynchronousQueue handoff, with no global lock on the common-case borrow. - FastList over ArrayList:
FastListtracks open statements;remove()walks from the tail becauseclose()usually targets the most recently opened statement. - Generated proxies, not reflective: proxy classes are generated with Javassist instead of
java.lang.reflect.Proxy, removing reflective dispatch from routine JDBC calls. - The lock the others still take: DBCP2’s
GenericObjectPool.borrowObject()serializes through its idle deque’s lock on eachpollFirst; Tomcat JDBC’sConnectionPool.borrow()serializes through its idle queue’s lock on each poll — both are the kind of borrow-time serialization HikariCP’s ThreadLocal layer skips. - Sizing rule: the project’s pool-sizing guidance recommends
minimumIdle == maximumPoolSizefor production so the bag rarely empties and falls through to layer-three handoff.

The opening visual makes the metaphor concrete: a single fiber passes a gate marked ConcurrentBag while parallel fibers slow at turnstiles labeled as synchronized borrow blocks. The rest of this article walks the actual Java classes behind that picture and shows the equivalent regions in DBCP2 and Tomcat JDBC where the turnstile is the locked section the bag refuses to enter.
The three structures that explain HikariCP’s acquisition win
Every connection pool has the same shape on paper: a set of Connection objects, a borrow method, a return method, a housekeeper that prunes idle entries. The interesting differences live one layer down — in how the pool represents that set and how a borrow walks it.
HikariCP’s Down the Rabbit Hole wiki page names three internal classes that do most of the work on the acquisition path:
com.zaxxer.hikari.util.ConcurrentBag— the collection that storesPoolEntryobjects. A borrow tries a thread-local list first, falls back to scanning a sharedCopyOnWriteArrayList, and only blocks on aSynchronousQueuewhen both miss.com.zaxxer.hikari.util.FastList— the list used by each proxy connection to track open statements. It drops the range-check exception path and walksremove()from the tail, becauseStatement.close()typically closes the most recently opened statement.com.zaxxer.hikari.pool.ProxyFactoryplus Javassist bytecode generation — proxies forConnection,Statement,PreparedStatement,CallableStatement, andResultSetare generated as ordinary classes at startup, so calls go through direct method dispatch instead ofjava.lang.reflect.Proxy‘s invocation handler.
None of these is a general-purpose tuning trick. Each one is shaped for a specific access pattern the pool produces millions of times a day: borrow from one thread at a time, return to the same thread soon after, close statements in roughly LIFO order, and call the same handful of JDBC methods over and over. DBCP2 and Tomcat JDBC use general-purpose collections and heavier per-call dispatch on those same paths, which is the structural reason their acquisition latency is higher under contention.
The diagram traces a single borrow through the three layers of ConcurrentBag: the per-thread cache check, the shared list CAS scan, and the queue handoff to a waiting thread. Each layer is a fallback, and the layer that handles the request determines what the borrow paid for. In a steady-state app, most borrows finish at layer one and never read shared state.
ConcurrentBag, layer by layer: how a borrow stays lock-free
The ConcurrentBag source on GitHub is short — a few hundred lines — and reading borrow(long timeout, TimeUnit unit) end to end is the fastest way to understand HikariCP’s acquisition story. The method does three things, in order.
Layer 1 — ThreadLocal cache. Every thread that has used the bag keeps a small list of entries it has previously borrowed and returned. The borrow walks that list from the most recent entry backwards and tries to atomically transition any STATE_NOT_IN_USE entry to STATE_IN_USE via compare-and-set. If one succeeds, the borrow returns immediately. No shared state was read. No lock was taken. In a steady-state application where the same threads keep recycling the same set of connections, this layer handles most acquisitions.
I wrote about lock-free data structure intuition if you want to dig deeper.
Layer 2 — shared list scan. On a miss, the borrow falls through to the shared CopyOnWriteArrayList of all PoolEntry objects. It walks the list and attempts the same CAS transition. The list itself is lock-free for readers; writers (add/remove of entries by the housekeeper) make a copy. There is no synchronized region on the read path.
Layer 3 — SynchronousQueue handoff. If the shared scan also misses, the borrow signals the pool to add a new connection (via the addBagItem listener) and waits on a SynchronousQueue until the timeout. A returning thread hands its entry directly to the waiting thread through that queue, with no intermediate storage. The handoff is the only point in the borrow path that can block, and it only fires when the bag is empty.
That three-layer structure is what keeps acquisition lock-free in the common case. The hot path reads no shared mutable state — only the thread’s own ThreadLocal reference and per-entry atomic state. The cold path uses a queue designed for direct producer-to-consumer handoff. The bag never sits in a synchronized block waiting for any other thread.
What DBCP2 and Tomcat JDBC do on the same path
Look at the equivalent borrow in org.apache.commons.dbcp2.PoolingDataSource.getConnection() and the picture is different. DBCP2 delegates to GenericObjectPool.borrowObject() from commons-pool2. The idle objects live in a LinkedBlockingDeque, and the borrow path uses pollFirst with timeout, which serializes acquisitions through the deque’s internal lock on each poll (see the GenericObjectPool source). The pool also tracks all objects in a ConcurrentHashMap keyed by the borrowed instance, so a borrow performs a hash map put on the hot path. Eviction, validation, and abandoned-connection tracking add further synchronized regions.
Tomcat JDBC’s ConnectionPool.borrow() is closer in spirit — it uses a BlockingQueue of idle PooledConnection objects — but it still serializes through that queue’s internal lock on each poll (see the ConnectionPool source), and it walks an interceptor chain on each borrow which dispatches through normal Java method calls. The interceptor chain is configurable and includes statement caching and slow-query interception. None of it is reflective, but every borrow still acquires a queue lock that HikariCP’s ThreadLocal layer would have skipped.
I wrote about failure handling around the pool if you want to dig deeper.
Neither pool is poorly written. Both reuse JDK concurrent primitives in the obvious way. The difference is that HikariCP designed a custom collection for the specific access pattern a pool sees — repeated borrow-return-borrow by the same thread, with rare transitions — instead of reusing BlockingQueue or ConcurrentHashMap as the storage substrate. The acquisition gap is the cost of “obvious” being one step less aggressive than “purpose-built”.
FastList and the Javassist proxy: why per-statement overhead matters
Acquisition is not the only path the pool touches. Every borrowed connection wraps the driver connection in a proxy, and every statement opened on that connection is tracked so a forgotten close() can be cleaned up when the connection returns. That bookkeeping runs on every JDBC call, not just on borrow, so a small per-call cost adds up to a measurable share of the pool’s CPU profile.
FastList is the list type each proxy connection uses to track its open statements. Compared with ArrayList it omits range-check exceptions on get(index), skips fail-fast modification checks, and implements remove(Object) by walking from the tail of the array rather than the head. The last choice is the most important: when a statement closes, the removal call almost always finds it near the end of the list because applications open and close statements in nested, last-in-first-out order. A head-walking search over several open statements tends to do more comparisons than a tail-walking one.
I wrote about GC pause behaviour on large heaps if you want to dig deeper.
The Javassist proxy is the other half. java.lang.reflect.Proxy dispatches every call through an InvocationHandler that receives a Method object and an argument array. Each call may allocate call-frame plumbing and reflect on the method. HikariCP avoids this by using Javassist at startup to generate concrete subclasses for each JDBC interface — HikariProxyConnection, HikariProxyPreparedStatement, and so on — that call the underlying delegate directly. The JIT sees ordinary call sites and can inline through them. DBCP2 and Tomcat JDBC both use proxy wrapping for the same broad purpose, so every prepareStatement() or setString() has more dispatch machinery on the hot path.
None of this matters at one query per second. At many thousand queries per second, with each query touching three or four proxied JDBC methods, the cost difference stops being rounding error.
Benchmarks that aren’t from 2017: methodology and what to measure
The HikariCP README still cites a JMH chart from an older release line. That chart predates several Java LTS releases and a generation of CPU microarchitecture, so citing it as evidence today is fair to nobody. A current benchmark for connection acquisition needs three things: a contended workload, modern pool versions, and reported tail latency rather than mean throughput.
A methodology that gives a number you can actually use for a decision:
If you need more context, trustworthy JMH harness setup covers the same ground.
- Start from the HikariCP-benchmark JMH harness — it isolates the borrow/return cycle from any actual database I/O.
- Pin pools at
maximumPoolSize=NwithminimumIdle=N, varying contended thread count across a wide range. Acquisition cost is dominated by contention, so single-thread numbers are not the relevant signal. - Run against a real database, such as a current PostgreSQL release, not an in-memory stub, because
isValid()and validation queries behave differently against a real network socket. - Report
p50,p95,p99, andp99.9per pool, not arithmetic mean. The differences live in the tail. - Re-run on a current LTS JDK with the platform-threads executor and the virtual-threads executor separately, because pinning behaviour changes the answer.
The terminal capture illustrates the shape of a JMH harness invocation for borrow/return cycles against PostgreSQL on a current LTS JDK. Specific ordering and ratios are not reproduced as a headline number here, because absolute values shift by JDK, CPU, driver, and pool configuration — which is exactly why an older README chart is no longer a reliable anchor. Run the harness against your own service to get figures that mean something for your decision.
The heatmap groups the same workload across thread counts and pool versions. The mechanism predicts the shape: pools that take a queue lock per borrow should fan out as contention rises, while HikariCP’s lock-free layers should be less sensitive to it. Whether that prediction holds at the magnitudes you care about is a question your own JMH run answers — and where a gap appears, it is a contention story rather than a baseline story.
Virtual threads and the ThreadLocal cache: is HikariCP still the right pick on Loom?
The open question on JEP 444 (virtual threads) is whether HikariCP’s ThreadLocal cache helps when each request runs on a fresh virtual thread. Virtual threads have their own ThreadLocal storage — they are not silently shared with the carrier — so a virtual thread starts with an empty layer-one cache and its first borrow falls through to the shared list. Once the virtual thread has borrowed and returned an entry, its own ThreadLocal does cache it, but virtual threads are typically scoped to a single request, so the cache may never see repeat traffic on the same thread.
Two structural facts still favor the bag under Loom. First, the layer-two path is also lock-free — a CAS over a copy-on-write list, not a synchronized region — so a layer-one miss does not fall straight to a queue lock. Second, HikariCP’s hot path avoids the kinds of synchronized blocks on JDBC objects that can cause carrier-thread pinning for virtual threads. DBCP2 and Tomcat JDBC are not known to pin from their own internals either, but their per-borrow queue locks still serialize acquisitions on the carrier — how much of Loom’s latency benefit that erodes for a given workload is not well characterized in public benchmarks and is worth measuring against your own service rather than reasoning about in the abstract.
A related write-up: virtual threads under Loom.
The pragmatic guidance: on a current LTS JDK with virtual threads, the existing reasons to prefer HikariCP — lock-free hot path, no pinning surface from the pool’s own internals — still apply. The shape of the gap relative to DBCP2 and Tomcat JDBC depends on workload and is best confirmed against your own service rather than borrowed from a third-party microbenchmark.
When DBCP2 or Tomcat JDBC is actually the right call
HikariCP is the right default for most Spring Boot and Jakarta EE applications today, and Spring Boot 2.0 already made it the default. That does not mean it is the right pick for every situation. A few cases where the other pools earn their place:
| Situation | Best fit | Why |
|---|---|---|
| High-concurrency borrow-heavy service, tight p99 latency budget, current LTS JDK | HikariCP | ConcurrentBag’s layered borrow keeps tail latency flatter under contention |
| Legacy app needing abandoned-connection tracking with removal of long-held connections | DBCP2 | DBCP2’s removeAbandoned with logAbandoned reports the offending stack trace; HikariCP’s leak detection logs but does not remove |
| Tomcat-embedded application already on Tomcat JDBC interceptors | Tomcat JDBC | The existing interceptor chain (statement caching, slow-query log) is not portable to HikariCP without rewriting |
| Low-QPS internal tool, single connection, Java 8 still required | Either | Acquisition cost is not the bottleneck; pick by familiarity. HikariCP 4.0.3 is the last 4.x release for Java 8; the Java 7 line lives in the separate HikariCP-java7 artifact, and the 5.x line moved to Java 11+ |
| Workload dominated by long-running queries, not borrow rate | Either | The pool is idle most of the time; statement-level differences do not register |
DBCP2’s removeAbandoned in particular is one feature HikariCP intentionally does not match — the project FAQ on abandoned-connection handling argues that a leak in application code should be fixed in application code, not papered over by the pool. That is a defensible stance but not a universal one; a third-party plugin you cannot patch is the case where DBCP2’s stance is more useful than HikariCP’s.
If you need more context, per-hop latency tradeoffs covers the same ground.
Configuring HikariCP so the bag stays hot
The mechanism shapes the configuration. If the borrow advantage lives in a ThreadLocal cache and a layered scan, the operational goal is to keep the bag full so layer-three handoff almost never fires. A few settings that follow directly from the mechanism:
// Illustrative HikariCP configuration for a Spring Boot service.
// Versions: HikariCP 5.x, current LTS JDK, Spring Boot 3.x.
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:postgresql://db.internal:5432/app");
config.setUsername("app");
config.setPassword(System.getenv("DB_PASSWORD"));
// Fixed-size pool: minIdle == maxPoolSize keeps layer-three handoff cold.
config.setMaximumPoolSize(20);
config.setMinimumIdle(20);
// Keep idle connections alive against firewall and DB idle timeouts.
config.setKeepaliveTime(30_000); // 30s, must be smaller than maxLifetime
config.setMaxLifetime(1_800_000); // 30 min, smaller than DB wait_timeout
// Leak detection logs but does not remove. Only enable in non-prod or when
// chasing a known leak; the listener allocates per borrow.
config.setLeakDetectionThreshold(0); // 0 = off in production
HikariDataSource ds = new HikariDataSource(config);
Three things to take from that snippet. First, minimumIdle equal to maximumPoolSize is the configuration the About Pool Sizing wiki recommends — a fixed-size pool means the housekeeper never thrashes and the bag never empties under a normal burst. Second, keepaliveTime and maxLifetime must both be smaller than your database’s idle timeout; on PostgreSQL that is idle_in_transaction_session_timeout, on MySQL it is wait_timeout. Third, leakDetectionThreshold adds a per-borrow scheduled task that allocates and cancels for every connection; it is fine for development but pays cost in production, where the leak signal usually already exists in your APM trace.
Related: pool metrics worth exporting.
The mental model is that any time the bag empties — because the pool was sized too small, or because maxLifetime expires too many entries at once — the borrow path falls off layer one, off layer two, and onto the SynchronousQueue handoff. The latency cliff you observe under load is almost always the bag going cold, not HikariCP being slow. Fix the cliff by sizing the pool against your real concurrency, not by chasing knobs.
If you take one thing from reading the source, take this: HikariCP’s reputation rests on the absence of a lock DBCP2 and Tomcat JDBC still take. Knowing that lets you predict where the gap will matter (borrow-heavy services with tight p99 budgets) and where it will not (long-query workloads where the pool is idle anyway), instead of cargo-culting “switch to Hikari” as an answer to every latency problem.
Further reading
- Brett Wooldridge — Down the Rabbit Hole (HikariCP wiki)
- ConcurrentBag.java (HikariCP source on GitHub)
- FastList.java (HikariCP source on GitHub)
- GenericObjectPool API — Apache commons-pool2
- GenericObjectPool source — Apache commons-pool
- Tomcat JDBC ConnectionPool source
- Tomcat JDBC Connection Pool documentation
- JEP 444: Virtual Threads (OpenJDK)
- HikariCP wiki — About Pool Sizing