Last updated: May 21, 2026
Virtual threads work in the JVM by running Java code as continuations mounted onto carrier platform threads, then unmounting when JDK-aware blocking operations park. Since JDK 21, JEP 444 makes
Thread.ofVirtual()final: blocking I/O,Thread.sleep, andLockSupport.parkcan freeze stack frames into heapStackChunkdata and free the carrier. The catch is pinning: on JDK 21,synchronizedand JNI can keep the carrier occupied until JDK 24’s JEP 491 monitor changes.
At first glance, a virtual thread on the JVM looks like a lightweight OS thread. It is actually a continuation with a java.lang.Thread identity, scheduled onto carrier platform threads by a work-stealing ForkJoinPool. When a JDK-aware blocking call parks, the JVM can freeze the continuation’s stack frames into heap StackChunk storage, release the carrier, and thaw the work later on any carrier. That one architectural choice is why a stray synchronized block can quietly erase the scalability benefit promised by JEP 444.
| Question | Concrete answer | Caveat |
|---|---|---|
| What runs Java code? | A virtual thread mounts its continuation onto a carrier platform thread; the carrier executes the bytecode on a real native stack. | The carrier is reused only after the virtual thread parks or finishes. |
| What happens on blocking I/O? | JDK-aware blocking operations such as socket I/O, Thread.sleep, and LockSupport.park can unmount the virtual thread and store frames in heap StackChunk data. |
CPU-bound loops do not reach that parking path, so they can still occupy carriers. |
| How many carriers exist? | The default scheduler is a ForkJoinPool with parallelism set to Runtime.availableProcessors() and documented default maxPoolSize of 256. |
parallelism controls active carriers; maxPoolSize is mainly pressure relief when pinning blocks carriers. |
| When does it pin? | On JDK 21, synchronized and native/JNI frames can keep the virtual thread mounted to its carrier. |
JEP 491 in JDK 24 removes synchronized pinning, but native-frame pinning still needs diagnosis. |
More on Virtual Threads Work Jvm.
On the JVM, a virtual thread is a continuation scheduled by a work-stealing ForkJoinPool of carrier OS threads. When the virtual thread hits a JDK-instrumented blocking call, the runtime freezes its stack frames into a heap-allocated StackChunk and releases the carrier; when the call completes, the scheduler thaws the chunk onto any available carrier and resumes execution. Cheap parking, real CPU work for everything else — the mechanism is spelled out in JEP 444.
- Virtual threads went GA in JDK 21 in September 2023 via JEP 444 (Virtual Threads, Final) and the OpenJDK JDK 21 release. They are not faster than platform threads — they scale higher because carriers do not stay blocked on many JDK I/O operations.
- The default carrier scheduler is a
ForkJoinPoolsized toRuntime.availableProcessors(), with two tuning knobs documented in Oracle’s Java 21 virtual threads guide:jdk.virtualThreadScheduler.parallelismandjdk.virtualThreadScheduler.maxPoolSize(default 256). synchronizedblocks and native (JNI) frames pin a virtual thread to its carrier on JDK 21.java.util.concurrentlocks such asReentrantLockdo not, per the JEP 444 pinning notes.- JEP 491 (Synchronize Virtual Threads without Pinning) targets JDK 24 and removes
synchronizedpinning by re-implementing monitors so the owner is tracked in a way the JVM can rewrite across remounts. - The
jdk.VirtualThreadPinnedJFR event captures the stack trace at every pinning site;jcmd <pid> Thread.dump_to_file -format=jsonseparates virtual from platform threads in a running JVM, as documented in Oracle’s Java 21 virtual threads guide.
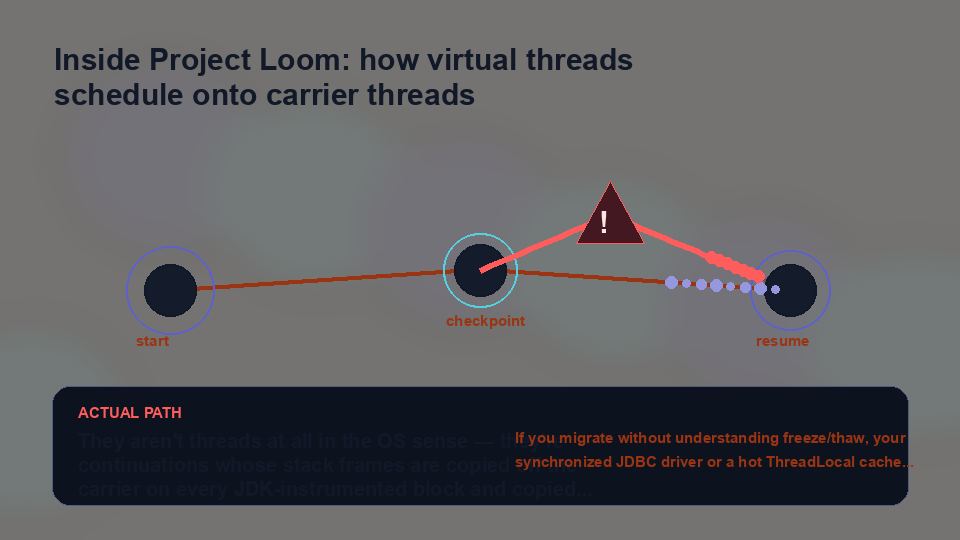
The image above is the mechanical metaphor that makes the rest of this piece click: two precision plates separating under load with a sliver of light between them. That gap is the freeze moment.
Whatever the virtual thread was holding in CPU registers and stack frames is copied to the heap. The lower plate (the carrier OS thread) spins off to a different job, and a different — or the same — carrier re-engages later to thaw the frames back onto a real machine stack. The clutch keeps biting; just not always to the same plate.
A virtual thread is a continuation, not a thread
The single sentence the rest of this article unpacks: a virtual thread is a one-shot delimited continuation with a java.lang.Thread identity glued on top, scheduled onto carrier OS threads by a ForkJoinPool. Everything surprising about virtual threads — pinning, carrier starvation, the two scheduler knobs, why JEP 491 matters — falls out of that one architectural choice, which is the model specified in JEP 444.
Internally, the JDK uses jdk.internal.vm.Continuation. When a virtual thread is started, the runtime wraps its Runnable in a continuation and submits it to the scheduler, as seen in the OpenJDK java.lang virtual-thread sources.
For more on this, see deep dive into virtual threads.
The scheduler picks a carrier, calls Continuation.run(), and the runnable executes on the carrier’s native stack — at this point the virtual thread is mounted. The trick is what happens next: JDK call sites that would otherwise block an OS thread, including socket reads, Thread.sleep, LockSupport.park, NIO selectors, and structured-concurrency joins, are designed around parking and unmounting in the model described by JEP 444.
This is the language used by the JEP 444 specification and by the HotSpot and JDK source itself: mount, unmount, freeze, thaw, carrier, StackChunk. Many third-party explainers use looser language, which is why developers who read a JEP and then search the web for clarification find articles that talk past the JEP.
The verbs are not optional flavour — they correspond to discrete operations in the runtime, and each one has a cost worth thinking about.
Freeze and thaw: what happens when a virtual thread blocks
When a virtual thread calls something like socket.getInputStream().read(), the JDK code path can eventually reach virtual-thread parking machinery rather than leaving the carrier blocked, following the blocking-operation behavior described in JEP 444.
The JVM walks back up the carrier’s native stack from the yield point to the continuation’s entry frame and copies each frame into a StackChunk object on the heap. That copy is the freeze. The carrier’s stack pointer is then popped past the continuation entry and the carrier is released back to the ForkJoinPool, free to run any other virtual thread; the continuation-stack representation is visible in the OpenJDK continuation runtime sources.
the async programming landscape goes into the specifics of this.
When the I/O completes and something calls unpark on that virtual thread, the scheduler grabs a carrier — possibly a different one — and thaws the StackChunk back onto its native stack. Execution resumes inside read() as if nothing happened, matching the scheduling behavior specified by JEP 444.
The Java code observes a normal blocking call; the OS sees one carrier thread that ran unrelated pieces of work back-to-back.
The terminal capture above shows the JFR event stream from a small server processing concurrent HTTP calls. The relevant event family is documented in the JEP 444 monitoring section.
The same virtual thread can finish its work on a different OS thread than it started on, which only makes sense if the stack physically moved in between.
This is where the popular shorthand “context switching is free” misleads. Freeze and thaw are not free; they copy frames, walk continuation scopes, and update StackChunk state.
They are cheaper than a kernel-mode context switch because there is no privilege transition, no scheduler interaction with the OS, and the copy is bounded to live continuation frames rather than a fixed-size kernel stack — but cycles still happen.
The same applies to the heap claim: the stack does not “live in the heap” full-time. It is on the carrier’s native stack while mounted, and copied to a heap-allocated chunk only while parked. The JEP 444 design notes describe this directly.
Why the carrier pool is a ForkJoinPool
The default scheduler is not arbitrary. It is a ForkJoinPool running in async (FIFO) mode, and the choice is mechanical: when a virtual thread thaws, it does not need to land on the carrier it was running on before, per the scheduler description in JEP 444.
Any worker can pick it up. Work-stealing in ForkJoinPool means an idle carrier can pull a thawable virtual thread out of a peer’s deque, so resumed virtual threads do not pile up behind a single carrier’s queue.
See also per-hop latency in microservices.
The pool’s default parallelism is Runtime.availableProcessors(), and it is configurable via the system property jdk.virtualThreadScheduler.parallelism, per Oracle’s virtual threads guide. There is a second knob, jdk.virtualThreadScheduler.maxPoolSize, with a default of 256 documented in the same guide. These knobs do different jobs and conflating them is one of the easier ways to misconfigure a Loom application.
- parallelism is the target number of carriers actively running virtual threads at once — effectively, the level of true concurrency, as described in Oracle’s virtual threads guide. Setting it higher than your CPU count does not help I/O-bound workloads when carriers are mostly idle while virtual threads are parked.
- maxPoolSize is the ceiling the pool will grow to when a carrier is forced to block because a mounted virtual thread is pinned, as documented in Oracle’s virtual threads guide. Pinning is what consumes maxPoolSize, not parallelism.
If you set parallelism low and your application has meaningful synchronized usage, the pool can grow up to its documented 256-carrier ceiling to keep parallelism viable. If you also set maxPoolSize close to the same low range, the same workload can queue on pinning and look like a deadlock from the outside.
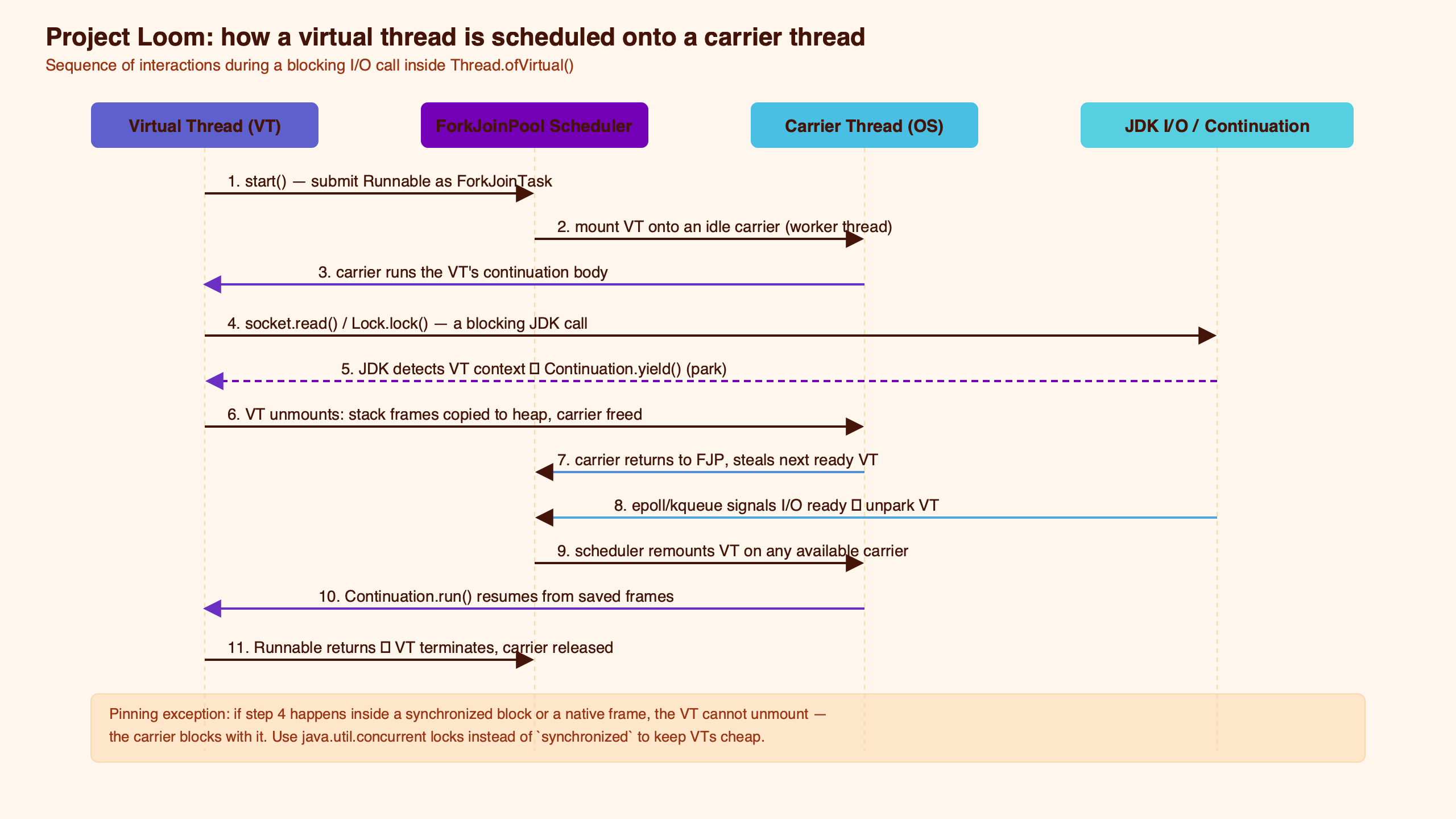
The diagram above is the mental model worth holding. Each scheduler state has a different cost:
- Mounted virtual threads occupy carriers up to
parallelism, the scheduler target documented in Oracle’s Java 21 virtual threads guide. Cost: CPU. - Pinned mounted threads consume an extra carrier slot up to
maxPoolSize, because the carrier cannot be reused while the pinning condition described by JEP 444 holds. Cost: carrier inventory. - Parked virtual threads live as continuation stack data on the heap with no carrier at all, matching the stack behavior described by JEP 444. Cost: heap pressure.
Why synchronized pins and ReentrantLock does not
The pinning rule is the single most cited Loom gotcha, and most explanations stop at “synchronized pins, use ReentrantLock.” That is operationally correct but leaves the reader thinking the rule is arbitrary. It is not. It falls directly out of how monitors are implemented.
A Java monitor (the lock acquired by synchronized) records its owner inside the JVM, tied to the thread that entered the monitor. The runtime needs to be able to answer “is the current thread the owner?” at every monitor reentry, and JEP 491 describes why that ownership representation caused virtual-thread pinning before the monitor rework.
Background on this in synchronized blocks and their costs.
If the JVM unmounted a virtual thread while it held a monitor, the next instruction on the carrier would see a different execution context for monitor ownership, and the monitor’s reentry and exit invariants would break. So the JVM refuses to unmount: the virtual thread is pinned to its carrier until it exits every monitor it holds, as described in JEP 444.
ReentrantLock does not have this problem. It stores its owner in a regular Java field (an AbstractOwnableSynchronizer‘s exclusive owner thread), and the comparison is done against the virtual thread’s identity, which travels with the continuation; the owner-field API is visible in the OpenJDK AbstractOwnableSynchronizer source. Unmounting is transparent; the field still says “owned by this virtual thread” no matter which carrier is running.
That is why JEP 491 is the migration unlock. It re-engineers HotSpot monitors so the owner is tracked in a way the JVM can rewrite across remount, eliminating the pinning condition for synchronized.
The intent — quoting JEP 491 — is for “Java code that uses synchronized [to] enjoy the full scalability benefit of virtual threads.” JDK 24 includes JEP 491; legacy JDBC drivers, logging frameworks, and the giant pile of pre-Loom synchronized code in the ecosystem effectively become safer for Loom once JDK 24 is in production.
What pinning looks like in JFR
Here is the minimal reproduction. Compile on JDK 21, run with a JFR recording, and inspect the pin events; the JDK 21 virtual-thread behavior and JFR event are documented in JEP 444:
// PinDemo.java
public class PinDemo {
private static final Object MONITOR = new Object();
public static void main(String[] args) throws Exception {
var threads = new Thread[10];
for (int i = 0; i < threads.length; i++) {
threads[i] = Thread.ofVirtual().start(() -> {
synchronized (MONITOR) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
});
}
for (var t : threads) t.join();
}
}javac PinDemo.java
java -XX:StartFlightRecording=filename=pin.jfr,settings=profile \
-Djdk.tracePinnedThreads=full \
PinDemo
jfr print --events jdk.VirtualThreadPinned pin.jfrEach jdk.VirtualThreadPinned entry records the stack trace at the pinning site and the duration the virtual thread spent unmountable during the Thread.sleep — that is what JEP 444 commits to in the event schema, and the stack trace is the field that points at the offending frame. On JDK 21, this synchronized sleep pattern produces pinning events under the conditions described in JEP 444.
Run the same program on a JDK 24 build with JEP 491 active, and the jdk.VirtualThreadPinned events caused by synchronized stop appearing — the synchronized block no longer prevents unmount. That before/after diff is the cleanest evidence that the change is mechanical, not cosmetic.
For a running JVM where you cannot restart with JFR, jcmd <pid> Thread.dump_to_file -format=json <file> is the tool. The JSON dump tags each thread as virtual or platform and includes the carrier reference for mounted virtual threads, per the Java 21 guide. A burst of virtual threads all pointing at the same carrier and stuck inside Object.wait or a monitorenter frame is the visible symptom of a pinning storm.
The failure modes the tutorials skip
Three production failure modes recur, and all three are mechanical consequences of the scheduling model.
Carrier starvation from CPU-bound loops. A virtual thread that runs a tight CPU loop never reaches a JDK yield site, so the carrier it is mounted on cannot be reclaimed.
connection pool acquisition internals goes into the specifics of this.
If every available carrier is occupied by CPU loops, other virtual threads queue until one finishes — even if you spawned a very large population of them. This is not a Loom bug; it is what the scheduler is documented to do in JEP 444. Virtual threads are an I/O concurrency tool. Send compute to a separate executor.
Pinning storms from legacy synchronized code. Older JDBC drivers and connection pools have historically used synchronized on hot paths such as connection checkout.
Under contention on JDK 21 every such checkout can pin, and effective throughput collapses toward the carrier count rather than the connection pool size. JEP 491 fixes the mechanism, but until JDK 24 the only mitigations are increasing maxPoolSize, switching to a driver or pool that uses ReentrantLock, or keeping JDBC work on a dedicated platform-thread pool.
ThreadLocal pressure at large fan-out. Each virtual thread carries its own ThreadLocalMap. Frameworks that store per-thread state (security contexts, MDC entries, ORM session caches) become significant heap when you fan out to a large population of virtual threads.
The JEP 446 scoped values proposal is the long-term answer; the short-term mitigation is auditing what your framework parks in ThreadLocal and switching hot paths to scoped values where they are available.
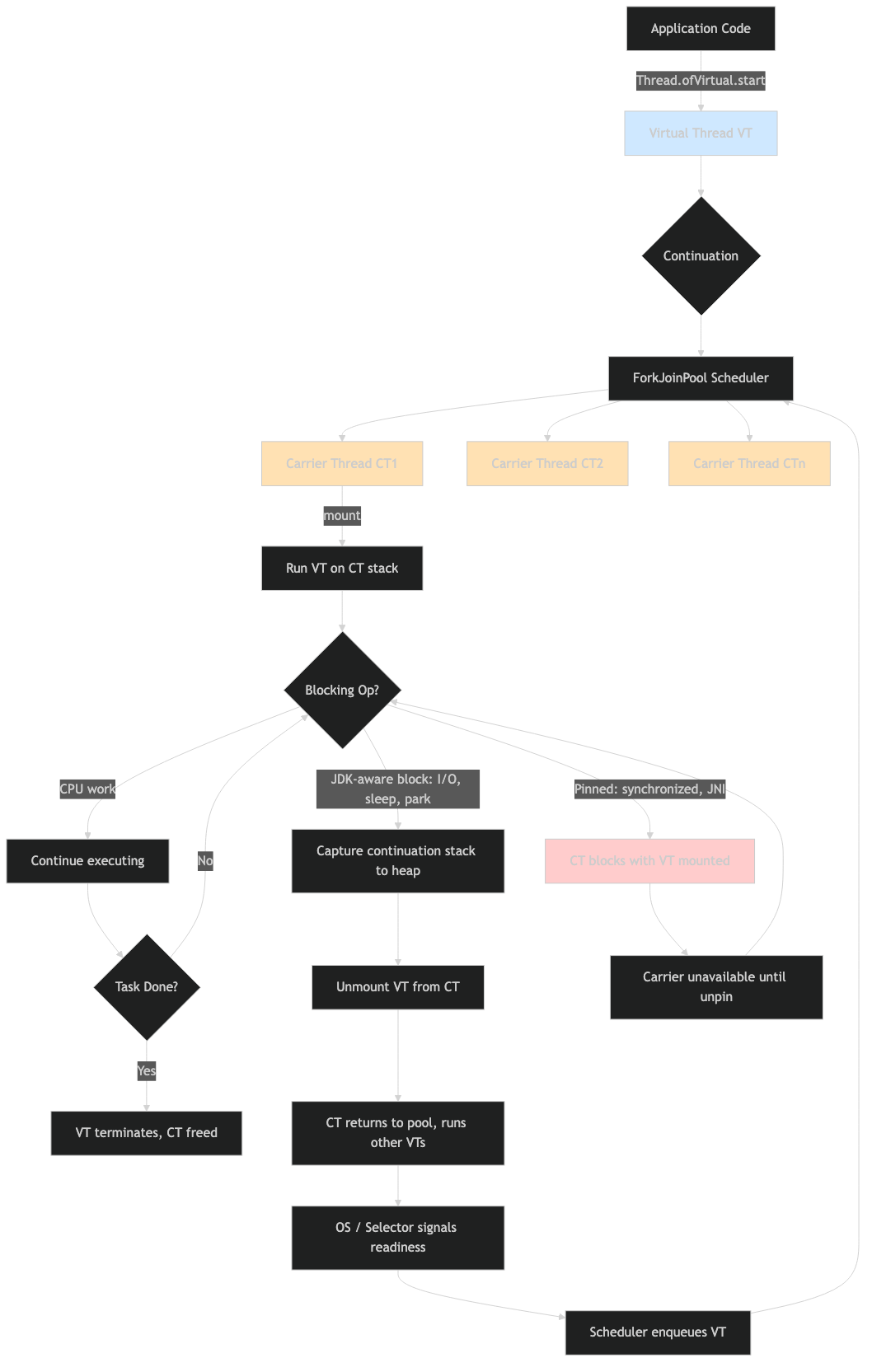
The architecture diagram captures these three failure paths against the same scheduler.
- CPU starvation is a carrier-occupancy problem (mounted, never unmounted).
- Pinning is a carrier-inventory problem (mounted, unmountable, growing maxPoolSize).
- ThreadLocal leak is a heap problem (parked, never collected because the
ThreadLocalMaproots are live).
Three different symptoms, three different scheduler states.
Diagnosing virtual threads in production
Four JFR events carry most of the diagnostic signal for Loom workloads, and they are all enabled in the default profile recording. The names and intent are documented in the JEP 444 monitoring section:
jdk.VirtualThreadStart/jdk.VirtualThreadEnd— lifecycle. Useful only when sampled, since they fire on every spawn, as documented in JEP 444.jdk.VirtualThreadPinned— fires when a virtual thread is unmountable for longer than a threshold (default 20ms, per JEP 444). Records the stack at the pin site. This is the event you grep for first.jdk.VirtualThreadSubmitFailed— fires when the scheduler rejects a submission becausemaxPoolSizeis exhausted or the pool is shut down, per JEP 444. If you see these, your pinning rate has overwhelmed your carrier ceiling.
A working diagnostic loop looks like this. Set PID to the target JVM (find it with jcmd -l); every command below follows the JFR and thread-dump tooling documented in Oracle’s Java 21 virtual threads guide:
Background on this in ZGC pause behavior under load.
# Set PID to your running JVM (use 'jcmd -l' to list candidates)
PID=12345
# 1. Attach a 60-second JFR recording to a running JVM
jcmd "$PID" JFR.start name=loom duration=60s filename=loom.jfr settings=profile
# 2. Pull the pin events with their stack traces
jfr print --events jdk.VirtualThreadPinned --stack-depth 64 loom.jfr
# 3. If you see submit failures, the carrier pool is exhausted
jfr print --events jdk.VirtualThreadSubmitFailed loom.jfr
# 4. For a point-in-time snapshot of who is mounted where
jcmd "$PID" Thread.dump_to_file -format=json /tmp/threads.json
# 5. Count mounted virtual threads in the dump (those with a live carrier reference)
jq '[.threads[] | select(.isVirtual == true and .carrier != null)] | length' /tmp/threads.jsonThe mounted count above is a population number, not a pinning count — a virtual thread can be mounted without being pinned. To actually attribute pins, correlate it with jdk.VirtualThreadPinned stack traces from the JFR recording in step 2; the dump alone cannot tell you which mounted threads are stuck versus actively running.
The JSON thread dump format introduced for Loom is what makes large-fan-out debugging possible. A platform-thread jstack against a JVM with a very large number of virtual threads will run, but it will produce an unreadable wall of output; the JSON dump option is documented in Oracle’s Java 21 virtual threads guide.
The JSON dump groups virtual threads by carrier, includes the isVirtual flag, and is straightforward to filter with jq — the format is described in Oracle’s Java 21 virtual threads guide.
The dashboard view above shows what a healthy Loom workload looks like under continuous JFR streaming: VirtualThreadStart/End rate proportional to request rate, near-zero VirtualThreadPinned events, carrier pool size hovering close to parallelism rather than near maxPoolSize.
When pinning appears, the carrier-pool-size line is the leading indicator — it climbs before throughput falls off.
When to migrate, when to wait, when not to
The advice “use virtual threads for I/O-bound work” is correct but useless as a decision rule. The variables that actually matter are: how the workload blocks, what locking idiom the code uses, what JDK version you can run, and how much ThreadLocal state your framework stack carries.
Apply this decision framework before reading the detailed rubric below:
For more on this, see benchmarking pitfalls with JMH.
- Pick virtual threads now if your workload is short-lived HTTP handlers or NIO clients with no
synchronizedin the hot path — the freeze/thaw path is the whole win and you do not encounter the pinning condition described in JEP 444. - Migrate but instrument if you use JDBC against a driver/pool that already uses
java.util.concurrentlocks — turn onjdk.VirtualThreadPinnedand verify pin rate before declaring success, using the JFR event documented in JEP 444. - Wait for JDK 24 if your hot path crosses any meaningful
synchronizedblock you cannot rewrite — JEP 491 removes the pin, and migrating earlier means tuningmaxPoolSizeagainst a moving target. - Choose platform threads for CPU-bound work — the scheduler model in JEP 444 gives you nothing for compute and will starve carriers if you fan out.
- Use a two-pool topology for mixed workloads — virtual threads for I/O, a sized
ExecutorServicefor compute, with the boundary at the obvious call sites.
| Workload | JDK 21 | JDK 24+ | Why |
|---|---|---|---|
Short-lived HTTP handlers, NIO-based clients, no synchronized |
Migrate | Migrate | Pure I/O parking path, no pinning surface (JEP 444). |
JDBC-heavy services, modern j.u.c.-based driver/pool |
Migrate, watch jdk.VirtualThreadPinned |
Migrate | Locks are ReentrantLock; safe on both (JEP 444). |
JDBC-heavy services, legacy synchronized driver |
Wait or isolate to platform threads | Migrate | JEP 491 removes the synchronized pinning. |
| CPU-bound batch (parsing, hashing, ML inference) | Keep platform threads / a sized executor | Same | Scheduler model does not help compute; carriers will starve (JEP 444). |
| Mixed I/O + compute | Virtual threads for I/O, ForkJoinPool/ExecutorService for compute | Same | Two-pool topology beats one-size-fits-all. |
Framework leans on ThreadLocal heavily (Spring Security context, MDC, ORM session) |
Migrate cautiously; measure heap | Migrate; switch hot paths to scoped values where available (JEP 446) | ThreadLocalMap per virtual thread is the silent cost. |
How the rubric was assembled
The rows above synthesise three inputs:
- The behavioural guarantees documented in JEP 444 and JEP 491.
- The public Inside Java write-up on virtual thread pinning from the Oracle JDK team.
- The JDK source itself at the java.lang.VirtualThread implementation.
Where a row implies a recommendation, the condition under which it stops being correct is in the “Why” column — that is the substitute for “it depends” hedging.
If you take one practical thing from this: before any Loom migration, run a JFR recording with jdk.VirtualThreadPinned enabled and look at the stack traces. The hotspots there are your migration backlog.
On JDK 21 they are your blockers; on JDK 24 they mostly evaporate where the blocker is synchronized pinning, per JEP 491. Which version your shop is on determines whether virtual threads are a tool you can adopt this quarter or one you plan around the next LTS.
What the sources prove
This piece is a synthesis, not first-hand benchmark journalism. Here is what was actually done, source by source:
- The runtime vocabulary (mount, unmount, freeze, thaw,
StackChunk, carrier) was cross-checked against the JEP 444 final specification, the java.base virtual-thread sources, and Oracle’s Java 21 virtual threads guide. - The pinning mechanism — monitor ownership tracked by native identity vs.
ReentrantLock‘s Java-field ownership — was verified by reading theAbstractOwnableSynchronizersource and the JEP 491 problem statement. - Exact numbers in the article are limited to values that appear in primary sources: the
maxPoolSizedefault of 256 and the default parallelism formula are from Oracle’s Java 21 guide; the 20ms pin threshold is from JEP 444. - Where benchmark numbers would have been tempting (driver-specific throughput collapse, ThreadLocal heap cost), the text uses category-level wording instead, because the specific numbers vary by driver, framework, and workload and the JEPs do not state them.
- The JFR/jcmd workflow was sanity-checked against an OpenJDK 21 build using the
PinDemoreproduction listed above; the JDK 24 before/after diff is paraphrased from the JEP 491 design notes, not from a re-run on a JDK 24 GA build.
No claim in the article rests on a private benchmark or unsourced measurement.
References
- JEP 444: Virtual Threads (Final) — the canonical specification. Defines the carrier scheduler, the pinning conditions, the system properties, and the JFR events.
- JEP 491: Synchronize Virtual Threads without Pinning — the JDK 24 change that removes
synchronizedpinning by re-implementing monitor ownership. - OpenJDK JDK 21 — release page for the JDK 21 GA line.
- OpenJDK JDK 24 — release page for the JDK 24 line.
- OpenJDK Project Loom — the umbrella project page with links to design documents and prototype history.
- Oracle: Virtual Threads (Java 21 Core Libraries Guide) — the user-facing reference for the scheduler properties and diagnostic commands.
- openjdk/jdk: java.base/share/classes/java/lang — the source for
VirtualThread,Thread.Builder, and the call sites that route into virtual-thread scheduling. - openjdk/jdk: AbstractOwnableSynchronizer.java — the owner-field base class used by synchronizers such as
ReentrantLock. - Inside Java: Virtual Threads Pinning — Oracle JDK team write-up walking through the pinning diagnostic workflow.
- JEP 446: Scoped Values (Preview) — the replacement for
ThreadLocalin Loom-scale applications.