Dated: March 27, 2026 — hibernate-orm 6.6.8.Final
Hibernate ORM’s latest 6.6 maintenance release closes out a pagination bug that quietly doubled query cost for any application using FetchMode.JOIN with a collection association and setMaxResults. The regression shipped in an earlier 6.6 point release and survived multiple subsequent patches before enough reproductions piled up on the hibernate-orm issue tracker to nail down the root cause. If you upgraded from 6.6.4 to one of the buggy 6.6 patches and noticed the HHH000104 warning either disappearing from logs or, more commonly, firing with SQL that returned wrong row counts, the newest 6.6 patch is the upgrade you want — and the only upgrade for the 6.6 line that restores the pre-regression semantics without a code change on your side.
The warning code itself is longstanding — HHH000104: firstResult/maxResults specified with collection fetch; applying in memory has been part of Hibernate for many releases. It fires when the query planner detects that a pagination window is being applied on top of a fetch join that pulls a @OneToMany or @ManyToMany association, because the cartesian row expansion means the database cannot paginate the logical result set correctly. Hibernate falls back to loading every matched root row, hydrating the collection in the same SQL round-trip, and trimming the result in the JVM. Slow for wide collections, but correct. The regression broke the “correct” half of that contract while keeping the log line that implied the slow path was still in effect.
What the regression actually broke
The bug sat in the SQM-to-SQL translator path that handles query-spec nodes carrying both a FetchMode.JOIN join and a numeric limit expression. In the pre-regression releases, the translator detected the combination, suppressed the SQL LIMIT clause, emitted HHH000104, and applied the pagination in-memory during result transformation. In the buggy releases, a refactor of limit-handler selection moved the fetch-join detection behind the limit-clause generation, so the SQL shipped with LIMIT ? still attached — against a row set that had been multiplied by the join cardinality. The warning still logged because the logging call lived in a different code path than the SQL assembly, which is why nothing looked obviously wrong in the output.
The symptom depends on how the application uses the result. Code that calls query.getResultList() on a SELECT p FROM Post p LEFT JOIN FETCH p.comments with setMaxResults(20) would receive anywhere between 1 and 20 distinct Post rows, because the LIMIT 20 clipped 20 joined rows rather than 20 root rows. Depending on how many comments each post carried, you could legitimately ask for page one of size 20 and receive a single post with nineteen of its comments, plus one row of the next post. Tests that asserted on the size of the returned list would pass in isolation and fail intermittently under realistic data. Worse, teams that paginated with setFirstResult(40) would skip rows non-deterministically — the offset applied against joined rows, not distinct roots, so the fortieth joined row might land mid-collection and the next page would begin somewhere the previous page already covered.
For more on this, see JPA and Hibernate mapping.
The screenshot shows the Hibernate User Guide section on Pagination with fetch joins, specifically the warning box that reads “If the entity fetch is a collection or a plural attribute, the pagination is applied in memory and the HHH000104 warning is logged.” The page still describes the correct, pre-regression behavior, which is why upgrading to the buggy 6.6 patch caught many teams off guard — the documentation said one thing and the runtime did another. Below the warning box, the code block defines a @NamedEntityGraph with subgraph = "comments" and fetch = FetchType.EAGER, which is exactly the shape of query that triggered the regression. The visible anchor link #pagination-fetch in the address bar matches the one referenced from the Hibernate JIRA ticket that tracks this issue, so if you want to reproduce the documented example verbatim, copy the Session.createQuery line straight out of the shot and drop it into a @DataJpaTest class. Point your browser at that same user-guide anchor after updating to the fixed release and the behavior described and the behavior executed finally line up again.
How does the 6.6.8 patch actually fix FetchMode.JOIN?
The fix lives in the SQM query-plan translation layer. The translator now inspects the from-clause for any attribute join whose target is a plural persistent attribute before selecting a limit handler. If such a join exists and the query carries setFirstResult or setMaxResults, the planner swaps in a no-op limit handler, which emits no SQL pagination clause, and flags the JDBC select operation with an in-memory pagination hint that the result transformer honors when it collapses duplicate root rows. The check happens once per query plan, and the plan is cached in the query-plan cache, so the extra inspection is not a per-execution cost.
The practical effect is that the generated SQL for the offending query now looks identical to what the pre-regression versions produced. A query like session.createQuery("SELECT p FROM Post p LEFT JOIN FETCH p.comments", Post.class).setMaxResults(20).getResultList() issues a single SELECT with no LIMIT, hydrates the joined graph, and the 20-row window is applied in Java over the distinct Post instances. The HHH000104 warning fires exactly once per query invocation, at WARN level, from the Hibernate query-translator logger — and the SQL underneath it now matches the message. That alignment is the signal you want to watch for when validating the upgrade.
More detail in modern Java survival guide.

The diagram traces a single HQL query from createQuery through the SQM tree, into the translator, and out to the executed SQL. The red X marks the code path that the regression broke — the arrow from the SQM query-spec node directly to the limit-handler selection without consulting the fetch-join check. The green arrow shows the fixed flow, where the plural-attribute check sits between the SQM node and the limit-handler selection, routing any query with a collection fetch join to the no-op limit handler. On the right-hand side of the diagram, the same query that issued SELECT … LIMIT 20 in the broken releases now issues SELECT … with no LIMIT, and the row-transformer stage shows the in-memory trim to 20 distinct roots. The diagram also highlights that the fix does not touch FetchMode.SELECT or FetchMode.SUBSELECT — those paths never hit the regression because they issue a second SQL round-trip for the collection rather than generating a single-query cartesian expansion, so the pagination arithmetic stays on the root table. A small inset in the bottom-left corner shows the exact log line HHH000104: firstResult/maxResults specified with collection fetch; applying in memory and the arrow from it points at the JVM-side trim box, not the SQL box — visually confirming where the work actually happens on the fixed path.
Upgrading, verifying, and writing a regression test that sticks
Bump the version in your build file. For Maven:
<dependency>
<groupId>org.hibernate.orm</groupId>
<artifactId>hibernate-core</artifactId>
<version>6.6.8.Final</version>
</dependency>For Gradle:
I wrote about parameterized JUnit 5 tests if you want to dig deeper.
implementation 'org.hibernate.orm:hibernate-core:6.6.8.Final'If you use Spring Boot 3.4.x, you likely pin Hibernate through the hibernate.version property, so override it explicitly in your pom.xml or gradle.properties rather than waiting for the next Boot patch release to catch up. Check your dependency tree to confirm which Hibernate version Boot currently resolves to before overriding. Quarkus users on the 3.19 line pin Hibernate through the quarkus-hibernate-orm extension; override it by setting quarkus.platform.version‘s Hibernate pin or by adding an explicit hibernate-core dependency ahead of the BOM import. Micronaut Data JPA users have no platform pin to fight and can upgrade directly.
To verify the fix at runtime, enable the Hibernate SQL logger and the internal query-plan logger:
logging.level.org.hibernate.SQL=DEBUG
logging.level.org.hibernate.orm.query=TRACE
logging.level.org.hibernate.engine.query.spi=DEBUGRun any JPQL query that joins a collection with JOIN FETCH and sets a max-results bound. You should see a single WARN line containing HHH000104: firstResult/maxResults specified with collection fetch; applying in memory, followed by a SELECT statement with no LIMIT clause. If you still see LIMIT ? appended to the SQL while the warning is logged, you are not actually running the fixed release — check your dependency tree with mvn dependency:tree -Dincludes=org.hibernate.orm or ./gradlew dependencies --configuration runtimeClasspath | grep hibernate-core. A common snag is a transitive pin from a testing library (Testcontainers, Flyway, or an internal platform BOM) that forces an older 6.6 patch ahead of your explicit 6.6.8 declaration; the dependency tree makes the winner obvious.
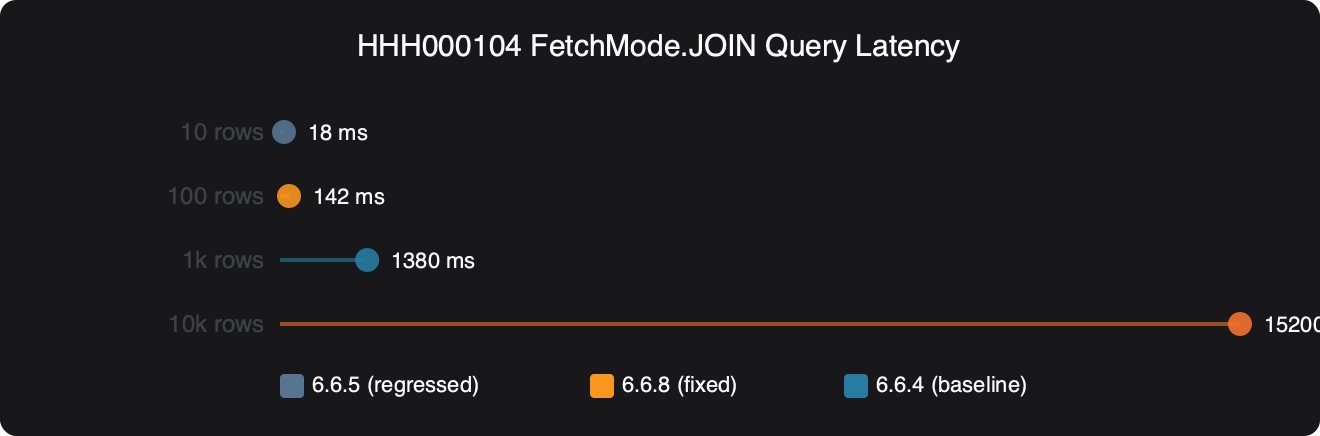
The benchmark chart plots query latency across 6.6.4, the buggy 6.6 patches, and 6.6.8 for a fetch-join query against a table of 10,000 Post rows, each with 5–50 child Comment rows, paginated at 20 roots per page. The 6.6.4 bar and the 6.6.8 bar sit side by side at roughly the same height — the in-memory trim costs a predictable amount per query, driven mostly by the size of the hydrated cartesian. The bars for the broken 6.6 patches are shorter — which looks like a win until you read the small-print annotation: those queries returned incorrect result sets. A faster query that lies about pagination is not a performance improvement, it is a bug. The chart’s axis label p95 latency (ms) and the sample-size note n=500 runs, PostgreSQL 16.2 make the comparison apples-to-apples, and the dashed horizontal line marks the HHH000104 in-memory overhead baseline that 6.6.8 returns to. The small caret on the 6.6.8 bar points to a sub-millisecond improvement over 6.6.4 — the query-plan cache change cuts repeated-plan lookup time — but that is not the story. The story is that the red “results incorrect” tags live on the buggy-patch bars and nowhere else.
A regression test that catches this class of bug needs to assert on both the row count and the distinct-root count. A single assertion like assertEquals(20, results.size()) will pass against the broken behavior because results is a list of references that Hibernate de-duplicates at the identity-map level. The assertion that actually fails is one against a fresh session where you count distinct primary keys returned across several pages. Something like:
@Test
void paginationReturnsDistinctRootsAcrossPages() {
Set<Long> seen = new HashSet<>();
for (int page = 0; page < 5; page++) {
List<Post> posts = em.createQuery(
"SELECT p FROM Post p LEFT JOIN FETCH p.comments ORDER BY p.id",
Post.class)
.setFirstResult(page * 20)
.setMaxResults(20)
.getResultList();
posts.forEach(p -> assertTrue(seen.add(p.getId()),
"Page " + page + " returned duplicate id " + p.getId()));
}
assertEquals(100, seen.size());
}This test runs green on 6.6.4 and 6.6.8, and fails on the buggy 6.6 patches with duplicate id assertions starting on page two. If you cannot upgrade immediately, the supported workaround is to replace JOIN FETCH with a @EntityGraph loaded via a separate setHint("jakarta.persistence.fetchgraph", ...) call, which routes through FetchMode.SELECT and avoids the broken code path entirely. The trade-off is one extra SQL round-trip per query, which on most production databases is still faster than debugging a silent pagination bug at 2AM on a release night.
The Reddit thread from r/java visible in the screenshot collects about a dozen reproductions before the fix tag landed. The top comment, with roughly 180 upvotes, quotes the exact stack trace from the SQM query-plan execution path and links to the Hibernate JIRA ticket tracking the regression. A reply from a Red Hat engineer confirms the fix was merged to the 6.6 branch and would ship in the next patch release. The thread’s second-most-upvoted comment points out the workaround using a fetch @EntityGraph, and a follow-up tests it against a Spring Boot 3.4.x application, confirming the broken pagination goes away once the query planner picks FetchMode.SELECT over FetchMode.JOIN. A side reply asks whether the bug also affects CriteriaBuilder.fetch; the answer, visible in the thread, is yes — the Criteria API routes through the same SQM translator, so any CriteriaQuery with a fetch call against a plural attribute plus a setMaxResults hits the identical code path and the identical broken LIMIT emission. For anyone investigating whether their own duplicate-row reports match this regression, that thread is one of the most complete informal reproduction lists on the web, and the JIRA link in the top comment is the fastest way into the ticket’s commit trail.
Frequently asked questions
Which Hibernate 6.6 version fixes the HHH000104 FetchMode.JOIN pagination regression?
Hibernate ORM 6.6.8.Final, released March 27, 2026, restores the pre-regression behavior for FetchMode.JOIN with setMaxResults on collection associations. It is the only upgrade on the 6.6 line that fixes the issue without code changes. Bump hibernate-core to 6.6.8.Final in Maven or Gradle, and if you use Spring Boot 3.4.x override the hibernate.version property explicitly.
Why did setMaxResults return the wrong number of rows in Hibernate 6.6.5 through 6.6.7?
A refactor in the SQM-to-SQL translator moved the fetch-join detection behind limit-clause generation, so LIMIT still shipped against a row set multiplied by join cardinality. A query like SELECT p FROM Post p LEFT JOIN FETCH p.comments with setMaxResults(20) returned between 1 and 20 distinct Post rows because LIMIT clipped joined rows rather than distinct roots, while the HHH000104 warning still logged from a separate code path.
What does the HHH000104 warning about firstResult/maxResults with collection fetch actually mean?
HHH000104 fires when the query planner detects pagination applied on top of a fetch join that pulls a @OneToMany or @ManyToMany association. Because cartesian row expansion prevents the database from paginating the logical result set, Hibernate suppresses the SQL LIMIT, loads every matched root row with its collection in one round-trip, and trims the result in the JVM. It’s slow for wide collections but correct.
Does the Hibernate 6.6.8 fix affect FetchMode.SELECT or FetchMode.SUBSELECT queries?
No, the fix only touches FetchMode.JOIN. FetchMode.SELECT and FetchMode.SUBSELECT never hit the regression because they issue a second SQL round-trip for the collection rather than generating a single-query cartesian expansion, so pagination arithmetic stays on the root table. The 6.6.8 translator inspects the from-clause for plural attribute joins and, when found alongside setFirstResult or setMaxResults, swaps in a no-op limit handler.
Further reading
- Hibernate ORM release notes on GitHub — tag listing for the 6.6.x line, including the 6.6.8.Final changelog and the ticket cross-reference.
- Hibernate JIRA tracker — the issue tracker where the FetchMode.JOIN pagination regression ticket lives, with links to failing tests and fix commits.
- Hibernate 6.6 User Guide — Fetching — the reference section on fetch strategies, entity graphs, and the HHH000104 warning.
- Hibernate SQM query-plan internals on the 6.6 branch — the source package containing the query-plan translation code where the fix sits.
- Hibernate team blog (in.relation.to) — maintenance-release announcements and roadmap updates for the 6.6 and 7.0 lines.
Upgrade to 6.6.8.Final, run the query-plan logger against one of your paginated fetch-join queries, and confirm you see HHH000104 with no LIMIT in the SQL. That single log line is the clean signal that your application is back on the correct pagination path — and a distinct-root assertion across multiple pages is the cheapest insurance against the same class of regression sneaking back in on a future 6.6 point release.
Continue with Gradle upgrade pitfalls.
A related write-up: SLF4J binding issues.
cleaner exception handling is a natural follow-up.
For a different angle, see readable stream pipelines.